What can I say? The founder of Keycloak Bill Burke himself somehow found this blog about Keycloak integration with Kubernetes way back when aaannndddd I completely missed it.
Bill, I’m very sorry, please accept my apology. Many reasons abound but the bottom line is, I’m honored you even read my post.
For those that don’t know (how dare you), Bill Burke created one of the greatest Identity and Access Management solutions. It was acquired/sponsored by Redhat sometime back.
Thanks Bill for all you do and keep up the great work.
I’ve been working on a little piece of software that determines Kubernetes DISA/STIG compliance. Written in Ansible, it prints out a report.html showing compliance of a given Kubernetes cluster. Super simple to run, just set KUBECONFIG as an environment variable.
EC2 user-data file should be generic – Having to modify user-data can cause major issues. Prefer to offload runtime based config to something like Ansible.
AWS VPC CNI for EKS is not required. Although its an interesting option, the choice to run an alternate CNI plugin is yours.
Kubernetes
Applications with slow startup times, should have a lower scaling (HPA) threshold so they can scale quickly enough to meet load demands.
Kubernetes clusters running multiple host sizes should ensure pods are tainted/tolerated to run on the correct hosts.
If automation of cloud services via Kubernetes is “in the cards” make sure all the dependencies can also be automated.
Example: I once automated the use of AWS ALBs, ELBs and Route53 DNS via Kubernetes. Eventually we chose to use Cloud Front as well but there is no automation for it via Kubernetes (at the time of this writing). This left us with maintaining cloud front manually or writing Terraform separately.
Language specific best practices:
NodeJS
Nodejs applications require 1 CPU and 1.5 GB of RAM by default. Make sure any application running nodejs has QoS set to 1 CPU and 1.75 GB of RAM. Nodejs apps without this run the risk of killing themselves because they assume they have the default regardless of what is set for QoS. The alternative is to modify the default resource requirements of Nodejs but many do not recommend doing this.
Nodejs applications more heavily utilize DNS to make requests as they don’t by default cache a DNS entry. This tends to cause a significant amount of load on Kubernetes DNS.
Java
Many Java applications utilize off-heap memory. Ensure QoS memory allocation for a Java app accounts for off-heap memory use.
Java 8 and older use the server CPU for determining how much CPU is available. It ignores the amount set by Docker. This can lead to crashing if the app attempts to consume more CPU than it is allowed.
Java 9+ can properly detect the correct CPU allocated.
Stackstorm (st2) is a platform which you can use as an automation framework. St2 has many features to support automating software development on-prem or cloud.
St2 packs are the units of content deployment and you can use different actions on pack(s) to create workflows.
In this blogpost, I’m going to demonstrate how to use st2 aws boto3 pack to manage services on aws.
Setup St2 environment
First of all you need to have a development environment with st2 installed. It is very easy to setup a vagrant box with st2. You can use the link below to setup the vagrant environment with st2 instantly.
Once you setup the environment, it is super simple to install a pack. There are hundreds of packs available for you to download and you also can contribute to the pack development. Use the link stated below to search a pack based on your needs. For example, may be you want ansible pack to deal with ansible via st2.
However, I want to install st2 aws pack in this occasion. You can simply search and copy the command to install the pack on stackstorm-exchange.
st2 pack install aws
This is one version of the aws pack which has lots of actions. The aws boto3 pack, by contrast, is more powerful and simple due to very valid reasons. The main reasons are simplicity and minimum or zero maintenance of the pack. Let’s assume that, boto3 action adds a new parameter in future, but aws.boto3action needs zero changes, i’d rather say that, this action is immune to the changes in boto3 action(s).
You can install the aws boto3 pack using the command below;
st2 pack install aws=boto3
In this pack, you just need only two actions to do anything on AWS that is why I said, it is very simple. Those two actions are;
aws.assume_role
aws.boto3action
The aws.assume_role action
This action is used to get the AWS credentials using AWS assume role. For example, see below code snippet.
In the preceding example, the aws.assume_role action has one input parameter which is AWS IAM role with proper permission. So basically, it needs to have required permission to perform various activities on AWS. For example, you may want to have ec2:* permission to manage EC2 related activities. It needs to have autoscaling:* permission to carry out autoscaling related activities so on and so forth.
Sample policy document for assume_role would be something like below;
When you pass an IAM role as assume role it returns AWS credentials and that credentials is saved in a variable to use at a later time. See the credentials variable under publish tag in the preceding yaml code snippet.
The aws.boto3action action
Let’s assume we need to get the information regarding a Launch Configuration. As per boto3, the relevant action to get Launch Configuration information is, describe_auto_scaling_groups. See the link mentioned below;
The describe_auto_scaling_groups action comes under AutoScaling service. Once you know these information you can interact this boto3 action within st2 as stated below;
region: The AWS region that you want to perform the action. service: The AWS service category. For example, ec2, autoscaling, efs,
iam, kinesis, etc. Check all the available service in boto3 using the link below;
action_name: Name of the boto3 action. In the above example, it is, describe_launch_configurations.
params: Input parameters for the action, describe_launch_configurations in this case. It has to be passed as a dict. You can refer the boto3 action to get a detailed explanation about the parameters and their data types. Please note that , lc_name is a input parameter which specifies the name of Launch Configuration.
You should feel free to poke around and see how this st2 aws boto3 pack works.
The aws.boto3action is used to execute relevant boto3 actions vis st2.
Summary
Six months ago, I started using st2. In fact Mike is the one who is responsible. He tasked me with database automation work using st2. So I definitely should thank him for that because I learned quite a bit.
The aws boto3 pack is designed with an eye towards the future, that is why it is protected from the changes in boto3 world which I believe is the most important factor when it comes software design. When you start using this pack, it will quickly become apparent how easy it is to use.
Today is my last day as a Principal Cloud Platform Architect at Pearson. Over the last few weeks I’ve had a bit of a retrospect on my time at Pearson. Our accomplishments, our failures, our team and all the opportunity it has created. I’m amazed how far we have come. I’m thankful for the opportunity and the freedom to reach beyond what many thought possible.
I left nothing on the table. I gave it all I had.
But one question still stands.
What IS Bitesize?
Bitesize is a platform purpose built for the future of Pearson.
Its a combination of interwoven technologies and application development methodologies that has resulted in advancements far beyond what any cloud provider can currently attain.
Its a team of engineers that believe, support and challenge themselves and others both in and outside the team.
Its a group of leaders that believe in their team and are willing to stick their neck out for what’s right.
Its a philosophy of change.
Its an evolving set of standards that increase fidelity of these interwoven pieces.
Bitesize is the convergence of disparate teams to make something greater than it could individually.
Its a treadmill of technology.
As I began thinking about what has been accomplished I decided to write down a few. I know I will leave many unsaid but hopefully this will give a view into just how much has been accomplished. Many may see this list and think one of two things: “That’s total bullshit, no way they did all that” or better yet “Ok I buy it, but have you reached nirvana?”
My answer to the former – “test your bullshit meter, its a bit off”
My answer to the latter – “as soon as one reaches a star, they realize how many other stars they want to reach”
A few achievements to date:
Fully automated platform and application upgrades
Completely scalable CI/CD pipeline treated as cattle (i.e. if they go away they self configure when they come back up)
Built-in log and data aggregation per Kubernetes namespace
Deep cloud provider integrations without lock-in
Fully automated database provisioning (containers and virtual machines)
Dynamic Certificate Management using Hashicorp Vault fully integrated with Load Balancers
100% availability for the platform and applications through critical business periods (to my knowledge this has not been achieved til now at Pearson)
Dynamic Application Configuration
Immutable Application architecture
OAuth into the platform and various infrastructure components
Universal API for single point of use
Audit Control and Compliance throughout the stack
Baked in Enterprise Governance
Highly secure, full BGP mesh cross geographic regions, capable of standing up new endpoints < 10 seconds
8.5 Million concurrent (and I do mean concurrent) user performance test, 150-250ms avg response
Enterprise Chargeback model
Dynamic CIDR provisioning (NSOT) for AWS and Kubernetes
In March of 2017, I wrote about Opaque Integer Resources whereby specific hardware capabilities could be used in Kubernetes. Alpha in 1.5, it allowed for the potential to enable resource like Last Level Cache, GPUs and Many Integrated Core devices etc etc.
In Kubernetes 1.8, Opaque Integer Resources were replaced with Extended Resources. This was a great move as it migrated from a kubernetes.io/uri model to allow resources to be assigned to any domain outside kubernetes.io and thus simply extend the API with API aggregation.
Extended Resources are a phenomenal start to vastly expand opportunities around Kubernetes workloads but it still had the potential to require modifications to Kubernetes core in order to actually use a new resource. And this is where Device Plugins come in.
Requirements:
Kubernetes 1.8
DevicePlugins enabled in Kubelet
Device Plugins
Device Plugins is a common framework by which hardware devices for specific vendors can be plugged into Kubernetes.
Think of it this way:
Extended Resources = how to use a new resource
Device Plugins = how vendors can advertise to and hook into Kubernetes without modifying Core
One of the first examples of Device Plugins in use is with Nvidia k8s-device-plugin. Which makes complete sense because Nvidia is leading an entire industry is various hardware arenas, GPU being just one of them.
Device Plugins are/should be containers running in Kubernetes that provide access to a vendor (or enterprise) specific resource. The container advertises said resource to Kubelet via gRPC. Because this is hardware specific, it must be done on a per node basis. However a Daemonset can be deployed to cover a multitude of nodes for the same resource across multiple machines.
The Device Plugin has three parts:
Registration – plugin advertises itself to Kubelet over gPRC
ListandWatch – provides list of devices and/or modifies existing state of device on change including failures
Allocate – device specific instructions for Kubelet to make available to a container
At first glance this may seem rather simple but it should be noted that prior to Device Plugins, Kubelet specifically handled each device. Which is where hardware vendors had to contribute back to Kubernetes Core to provide net new hardware resources. With device plugin manager, this will be abstracted out and responsibility will lay on the vendor. Kubelet will then keep a socket open to ListandWatch for any changes in device state or list of devices.
Use of new devices through Extended Resources
Once a new Device Plugin is advertised to the cluster. It will be quite simple to use.
Now lets imagine we are using Nvidia’s GPU device plugin at nvidia.com/gpu
Here is how we allocate a gpu resource to a container.
Integers Only – this is common in Kubernetes but worth noting. 1 for gpu above can not be 0.5.
No Overallocation – Unlike Memory and CPU, devices can not be over allocated. So if Requests and Limits are specified, they must equal each other.
Resource Naming – I can’t confirm this but playing around with nvidia gpu I was unable to create multiple of the same device across multiple nodes.
Example:
I had difficulty advertising nvidia.com/gpu on node 2 once it was advertised on node one.
If correct, this would mean I would need to add nvidia.com/gpu-<node_name> or something of that measure to add the gpu device for multiple servers in a cluster. And also call out that specific device when assigning to the container requiring the resource. Now keep in mind, this is alpha so I would expect it to get modified rapidly but it is currently a limitation.
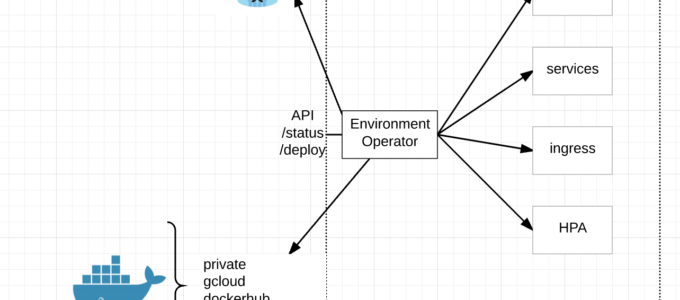
The day has finally come. Today we are announcing our open source project Environment Operator (EO).
Environment Operator is used throughout our project and has rapidly gained a name for itself as being well written and well thought out. Props go out to Simas Cepaitis, Cristian Radu and Ben Somogyi who have all contributed.
At its core, EO enables a seamless application deployment capability for a given environment/namespace within Kubernetes.
Benefits/Features:
multi-cluster deployments
audit trail
status
consistent definition of customer environments
separate build from deploy
minimizes risk and scope of impact
simple abstraction from Kubernetes
BYO CI/CD
empowers our customers (dev teams)
API interface
multiple forms of authentication
deploy through yaml config and API
written in Go
Docker Registries
Multi-Cluster Deployments –With EO running in each namespace and exposed via an API, CI/CD pipelines can simply call the API endpoint regardless of Kubernetes cluster and deploy new services.
API Interface –EO has its own API endpoint for deployments, status, logs and the like. This combined with a yaml config for its environment is a very powerful combination.
Audit Trail –EO provides an audit trail of all changes to the environment through its logging to stdout.
Status –EO provides a /status endpoint by which to understand the status of an environment or individual services within the environment with /status/${service}
Separate Build from Deploy –What we found was, while our CI/CD pipeline is quite robust it lacked real-time feedback and audit capabilities needed by our dev teams. Separating our build from deploy allowed us to add in these additional features, simplify its use and enabled our dev teams to bring their own familiar pipelines to our project.
Minimize Risk and Scope of impact –Because EO runs inside the Kubernetes cluster we could limit its capabilities through Kubernetes service accounts to only its namespace. This limits risk and impact to other dev teams running in the same cluster as well as requiring a dev to call and entirely wrong API endpoint in order to effect another environment. Further more, authentication is setup for each EO, so separation of concerns between environments can easily be made.
Simple Abstraction –Because EO is so simple to use, it has enabled our teams to get up and running much faster in Kubernetes. Very little prior knowledge is required, they can use their same pipelines by using a common DSL in our Jenkins plugin and get all the real-time information all from one place per environment.
BYO CI/CD –I think this is pretty self-explanatory but we have many dev teams at Pearson that already have their own CI/CD pipelines. They can continue using their pipeline or choose to use ours.
Empower our Dev teams –Ultimately EO is about empowering Dev teams to manage their own environments without requiring tons of prior knowledge to get started. Simply deploy EO and go.
Authentication –EO currently supports two different kinds of authentication. Token based which gets pulled from a Kubernetes secret or OAuth. We currently tie directly into Keycloak for auth.
Plugin (DSL) for Jenkins –Because most of our Dev teams run Jenkins, we wrote a plugin to hook directly into it. Other plugins could very easily be written.
Docker Registries –EO can connect to private, public, gcloud and docker hub registries.
As you can see, Environment Operator has a fair amount of capabilities built-in but we aren’t stopping there.
Hello! My name is Matt Halder and I’ve had some interesting experiences working in a variety of IT fields. I started out working at a Government Contractor in Washington, D.C as a Networker Controller; moved my way up to Network Engineer and finished as a Lead Technologist. From there, headed westward to Denver, CO for an opportunity to work at Ping Identity as a Security Operations Engineer. Currently, I work at FullContact as DevOps Engineer. The FullContact team has been using kubernetes in production for the last seven months as a way to reduce our overall cloud hosting costs and move away from IaaS vendor lock-in. Both the development and staging clusters were bootstrapped using kops. The largest barrier to adoption that was echoed throughout the development team was needing the ability to tail logs. When role-based access control was introduced in kubernetes 1.6, the ability to provide access to the cluster outside of shared tokens, certs, or credentials became a reality. Here are the steps that were used to enable openid-connect on kubernetes.
When setting up an OpenID Connect provider, there are few terms to be aware of. First is the “IdP”, which is the identity provider; many technologies can be used as an identity provider such as Active Directory, Free IPA, Okta, Dex or PingOne. Second is the “SP”, which is the service provider; in this case the service provider is the kubernetes API. The basic overview of an OpenID Connect workflow is this: the user authenticates to the IdP, the IdP returns a token to the user, this token is now valid for any SP that is configured to use the the IdP that produced the token.
Set up your IdP with an openid-connect endpoint and acquire the credentials.
Configure the SP [aka configure the API server] to accept openid-connect tokens and include a super-admin flag so that existing setup will continue to work throughout the change.
Generate kubeconfig file including oidc user config.
Create role bindings for users on the cluster.
Ensure all currently deployed services have role bindings associated with them.
Step 1: Set up the IdP
Since G Suite is already in place, we had an IdP that could be used for the organization. The added benefit is this IdP is pretty well documented and supported right out of the box, the caveat being that there is no support for groups so each user will need their own role binding on the cluster.
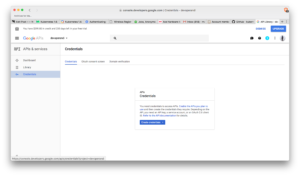
Navigate to https://console.developers.google.com/projectselector/apis/library.
From the drop-down create a new project.
The side bar, under APIs & services -> select Credential.
Select OAuth consent screen (middle tab in main view). Select an email and choose a product name, press save.
This will take you back to the Credentials tab (same as the screenshot above). Select OAuth clientID from the drop-down.
From application type -> select Other and give a unique name.
Copy the clientID and client secret or download the json. Download is under OAuth 2.0 client IDs on the right most side.
Step 2: Configure the SP [aka configure API Server] to accept OIDC tokens
Kops now has the ability to add pre install and post install hooks for openid-connect. If we were starting from scratch, this is the route that would be explored. However, adding these hooks didn’t trigger any updates and forcing a rolling update on a system running production traffic was too risky and was untested since staging had tested/updated prior to this functionality being introduced.
Kubelet loads core manifests from a local path, the kops clusters kubelet loads from /etc/kubernetes/manifests. This directory stores the kube-apiserver manifest file that tells kubelet how to deploy the api server as a pod. Editing this file will trigger kubelet to re-deploy the API server with new configuration. Note, this operation is much riskier on a single master cluster than on a multi master cluster.
Kubelet should re-deploy the API server within a couple of minutes of the manifest being edited.
Ensure that network overlays/CNI is functioning properly before proceeding, not all overlays shipped with service accounts and role bindings. This caused some issues with early adopters to kubernetes 1.6 (Personally, I had to generate a blank configmap for calico since it would fail if one wasn’t found).
Step 3: Generating a kubeconfig file
This process is broken into two steps, the first is to generate the cluster and context portion of the config while the second part is having the user acquire their openid-connect tokens and add them to the kubeconfig.
While opinions will vary, I’ve opted to skip the TLS verifications on the kubeconfig. Reasoning being is this would require a CA infrastructure to generate certs per users which isn’t in place.
There’s a bit of a chicken and egg thing going on here where kubectl needs to be installed so that a kubeconfig can be generated for the kubectl (although that’s how ethereumwallet is installed so maybe it’s just me). Either way, this script can be edited with correct context and endpoints to generate the first half of the kubeconfig:
#!/usr/bin/env bash
set -e
USER=$1
if [ -z "$USER" ]; then
echo "usage: $0 <email-address>"
exit 1
fi
echo "setting up cluster for user '$USER'"
# Install kubectl dependency
source $(dirname $(readlink -f "$0"))/install_kubectl.sh 1.6.8
# Set kubeconfig location the current users home directory
export KUBECONFIG=~/.kube/config
# Set cluster configs
kubectl config set-cluster cluster.justfortesting.org \
--server=https://api.cluster.justfortesting.org \
--insecure-skip-tls-verify=true
#Set kubeconfig context
kubectl config set-context cluster.justfortesting.org \
--cluster=cluster.justfortesting.org \
--user=$USER
kubectl config use-context cluster.justfortesting.org
To generate the second part of the kubeconfig, use k8s-oidc-helper from here to generate the user portion and append the output at the bottom of the config file. Now, with a functioning kubeconfig the user needs a role binding present in the cluster to have access. The IdP client-id and client-secret will need to be made available to users so they can generate the openid-connect tokens. I’ve had good success with LastPass for this purpose.
Step 4: User Role Bindings
Now, create a default role that users can bind to. The example gives the ability to list pods and their logs from the default namespace.
Now, bind users to this role (notice the very last line has to be identical to the G Suite email address that used in Step 3).
At our organization, these files are generated by our team members and then approved via github pull request. Once the PR has been merged into master, the role bindings become active on the clusters via jenkins job.
Step 5: Existing tooling needs an account and binding
The last step is necessary for any existing tooling in the cluster to ensure continued functionality. The “–authorization-rbac-super-user=admin” flag from step 2 was added to ensure continuity throughout the process. We use helm to deploy foundational charts into the cluster; helm uses a pod called “tiller” on the cluster to receive all specs from helm sdk and communicate them to the API, scheduler, and controller-manager. For foundational tooling such as this, use service accounts and cluster role bindings.
Over the last few months I’ve been diving into various Serverless/FaaS architectures that can run on Kubernetes. To say this space has exploded would be a severe understatement. The number of amazing developers working in this space is remarkable. Much less the number of them integrating with Kubernetes.
I’m not going to talk about wrappers around Lambda (which there are a TON of). I’m talking about true FaaS capabilities that can at least demonstrate they run on Kubernetes.
I’ve worked with several of these now but I’ll point out the ones I’ve not as we go along. In most circumstances I was able to reduce the number of candidates to explore simply by reviewing their architectures to understand their pros and cons.
I’ve also come across what I believe will be some key indicators we may want to be aware of before taking on one of these capabilities.
Language support
Performance and Scalability (how quickly can a basic function execute)
Asynchronous/Synchronous support
Monitoring
Architecture
OpenWhisk
OpenWhisk was built and designed by IBM. Seems to be gaining a fair amount of traction in this space and has a good reputation. An excellent overview of the OpenWhisk Architecture can be written by Markus Thömmes , an OpenWhisk contributor at medium.com.
Language Support – OpenWhisk has full language support for just about anything. It even has integrations with Swift, Cloudant, Slack and YouTube.
Performance and Scalability – I found performance of OpenWhisk to be somewhat sluggish out of the box. But Mark provides some pretty good ways to increase performance here. Scalability is quite good as all components including the controllers can be scaled out.
Asynchronous/Synchronous – Asynchronous Only. Sounds like there are some plans for (semi?) synchronous support.
Monitoring – IBM does have Dashboard that can be use with IBM Bluemix and the CLI can be used for gaining insights as well but built-in capabilities with open source monitoring platforms are non-existent.
Architecture –
CouchDB and Kafka are in direct line of the execution for any function. CouchDB being for both authentication and action retrieval. Personally I couldn’t see us requiring Authentication through OpenWhisk and I would imagine most others have their own Auth capabilities that support far more than what are offered here. Kafka because all requests are Asynchronous (at this time).
Primary problem the with the above is availability. The more stateful (semi or otherwise) services required to be available, the more opportunity for failure however you’ll find this is fairly common in FaaS. Some sort of message queue and some sort of storage for holding code. This tends to limit the number of languages (and/or versions) supported but IBM have done a good job here. Basically any container can be an invoker as long as it conforms to a few specifics.
Notes for OpenWhisk on Kubernetes:
No use of Kubernetes scheduling.
OpenWhisk controller talks directly with the Docker API on the host, thus limiting scalability to what that host can handle. Also not going to work for availability.
Recap: Overall OpenWhisk is a platform that’s been around for a little bit now. It largely resembles Lambda in its capability but open to the masses. I could see OpenWhisk being used in very large FaaS implementations but its number of dependencies in the critical path scare me. Its performance could use some enhancing out of the box. But for a FaaS that relies on injecting functions into containers, its language support is stellar and it has some pretty cool direct integrations.
Bottom Line: I can’t recommend this platform if running Kubernetes at this time.
Kubeless
Kubeless is almost a brand new project. As of the time of this writing, Kubeless has only been committed to in any earnest for the last 5 months. They are truly Kubernetes native and plug right in to the Serverless project. I did not get the chance to really test out this platform but I’m aiming to get a handle on it in the next few weeks.
Language Support – Python and NodeJS
Performance and Scalability – I just don’t know yet
Asynchronous/Synchronous – Both
Monitoring – Baked in monitoring with Prometheus.
Architecture –
Kubeless relies heavily on built-in Kubernetes capabilities such as ThirdPartyResources (or Custom Definitions depending on version of Kubernetes) and takes advantage of the built-in API server. Everything to run a function exists in the ThirdPartyResource. As a result however, the Kubeless team has to provide support by language/version for functions to run. My hope is they will make this a bit more generic to allow customer runtimes? Otherwise I fear they won’t be able to keep up.
Correction: Executions with Kubeless are through http or triggered events. Thank You @sebgoa for pointing this out.
Notes: Kubeless has an easily consumable UI and directly plugs in to the Serverless Framework.
Kubeless runs on vanilla Kubernetes, OpenShift and hooks seamlessless into Kubernetes-RBAC for security.
Recap: Really cool new up and coming project integrating deeply with Kubernetes. Could be a heavy contender in the future.
Bottom Line: Not yet unless you are solely Python and NodeJS based.
IronFunctions
IronFunctions are the current unsung heroes in my mind. Under heavy development starting in July of 2016, this is an easily consumable open source project that integrates well with Kubernetes while having the unique ability to run Lambda style functions as well. So for all you Lambda junkies wanting to break your addiction, this might be a pretty damn good option.
Language Support – Only limited by the docker containers you can dream up.
Performance and Scalability – Only limited by the infrastructure its running on. I quite easily executed it in several languages both locally and on a full cluster in the 200-250ms range for Synch requests and 300ish for Asynch. I don’t see any scalability issues at this time. If a ceiling was hit, it would be quite easy to simply spin up a new IronFunctions capability in a different namespace in Kubernetes.
Asynchronous/Synchronous – Both
Monitoring – Logs
Architecture –
IronFunctions are a truly well built platform that I’m hesitant to say could serve many different use cases. There are a few basic components to running IronFunctions.
IronFunctions – Essentially the controller/API that manages incoming requests and starts up resources/container to fulfill said request.
Database – for configuration only. Not in the critical request path.
Message Queue – For Asynchronous requests.
Notes: Has a usable UI for managing functions. HotFunctions are pretty awesome. The CLI is very easy to use.
All in all, IronFunctions was the dark horse that surprised me by a long shot. I would love to see Prometheus monitoring make it in as I’m not terribly excited about Logging being the metrics collection point. Overall, minor gripe.
Recap: I was noticeably surprised by its scalability, performance and maturity for a project I just happen to run across. It has all the makings of a truly scalable, production capable FaaS offering. With Synchronous, Asynchronous AND HotFunction capabilities, I was very impressed. Combine that with ease of use, just enough integration with Kubernetes and I’m pretty much sold. Keep up the good work.
Bottom Line: Of the ones I’ve reviewed so far, a definite Yes. Just get me some metrics into Prometheus. 😉
In a future post I’ll have a look at Fission, Funktion and maybe an up and comer by alexellis called faas-netes.