Authentication is often that last thing you decide to implement right before you go to production and you realize the security audit is going to block your staging or more likely production deploy. Its that thing that everyone recognizes as extremely important yet never manages to factor into the prototype/poc. Its the piece of the pie that could literally break a entire project with a single security incident but we somehow manage to accept Basic Authentication as ‘good enough’.
Now I’m not going to tell you I’m any different. In fact, its quite the opposite. What’s worse is I’ve got little to no excuse. I worked at Ping Identity for crying out loud. After as many incidents as I’ve heard of happening without good security, you would think I’d learn my lesson by now. But no, I put it off for quite some time in Kubernetes, accepting Basic Authentication to secure our future. That is, until now.
Caveat: There is a fair amount of complexity so if you find I’ve missed something important. PLEASE let me know in the comments so others can benefit.
Currently there are 4 Authentication methods that can be used in Kubernetes. Notice I did NOT say Authorization methods. Here is a very quick summary.
- Client Certificate Authentication – Fairly static even though multiple certificate authorities can be used. This would require a new client cert to be generated per user.
- Token File Authentication – Static in nature. Tokens all stored in a file on the host. No TTL. List of Tokens can only be changed by modifying the file and restarting the api server.
- Basic Authentication – Need I say more? very similar to htpasswd.
- OpenID Connect Authentication – The only solution with the possibility of being SSO based and allowing for dynamic user management.
Authentication within Kubernetes is still very much in its infancy and there is a ton to do in this space but with OpenID Connect, we can create an acceptable solution with other OpenSource tools.
One of those solutions is a combination of mod_auth_openidc and Keycloak.
mod_auth_openidc – an authentication/authorization module for Apache 2.x created by Ping Identity.
Keycloak – Integrated SSO and IDM for browser apps and RESTful web services.
Now to be clear, if you were to be running OpenShift (RedHat’s spin on Kubernetes), this process would be a bit simpler as Keycloak was recently acquired by Red Hat and they have placed a lot of effort into integrating the two.
The remainder of this blog assumes no OpenShift is in play and we are running vanilla Kubernetes 1.2.2+
The high level-
Apache server
- mod_auth_openidc installed on apache server from here
- mod_proxy loaded
- mod_ssl loaded
- ‘USE_X_FORWARDED_HOST = True’ is added to /usr/lib/python2.7/site-packages/cloudinit/settings.py if using Python 2.7ish
Kubernetes API server
- configure Kubernetes for OpenID Connect
Keycloak
- Setup really basic realm for Kubernetes
KeyCloak Configuration:
This walk-through assumes you have a Keycloak server created already.
For information on deploying a Keycloak server, their documentation can be found here.
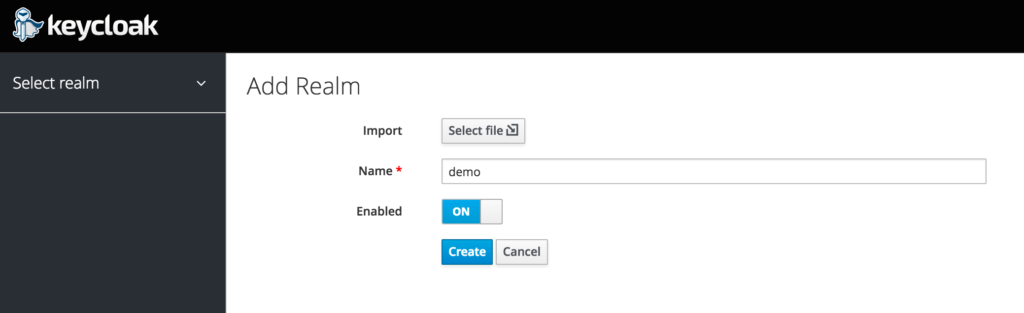
First lets add a realm called “Demo”
Now lets create a Client “Kubernetes”
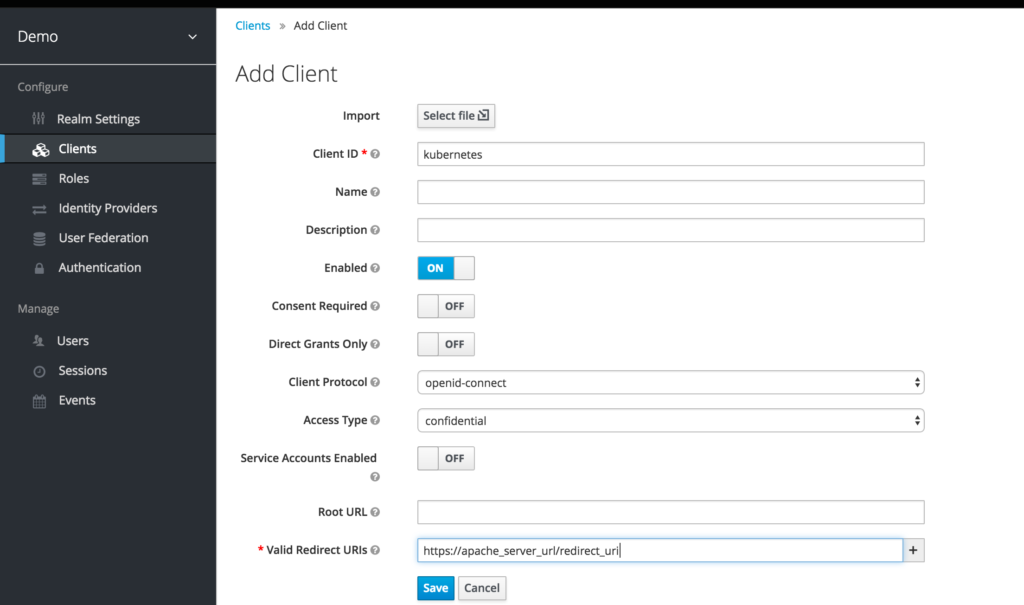
Notice in the image above the “Valid Redirect URIs” must be the
Apache_domain_URL + /redirect_uri
provided you are using my templates or the docker image I’ve created.
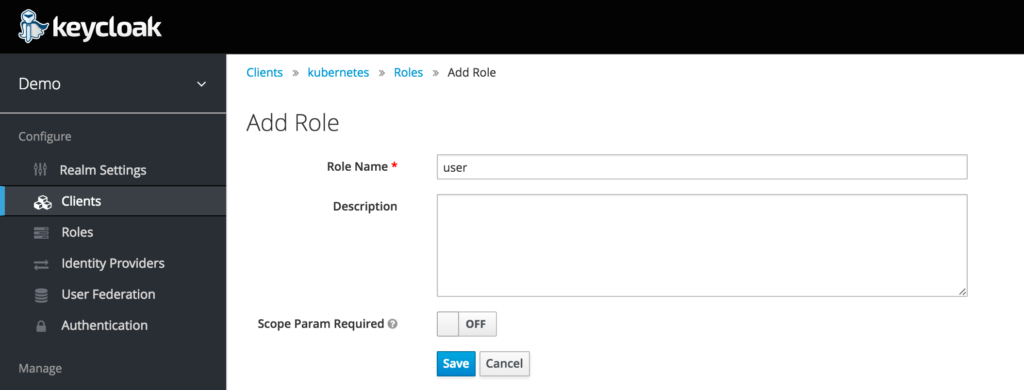
Now within the Kubernetes Client lets create a role called “user”
And finally for testing, lets create a user in Keycloak.
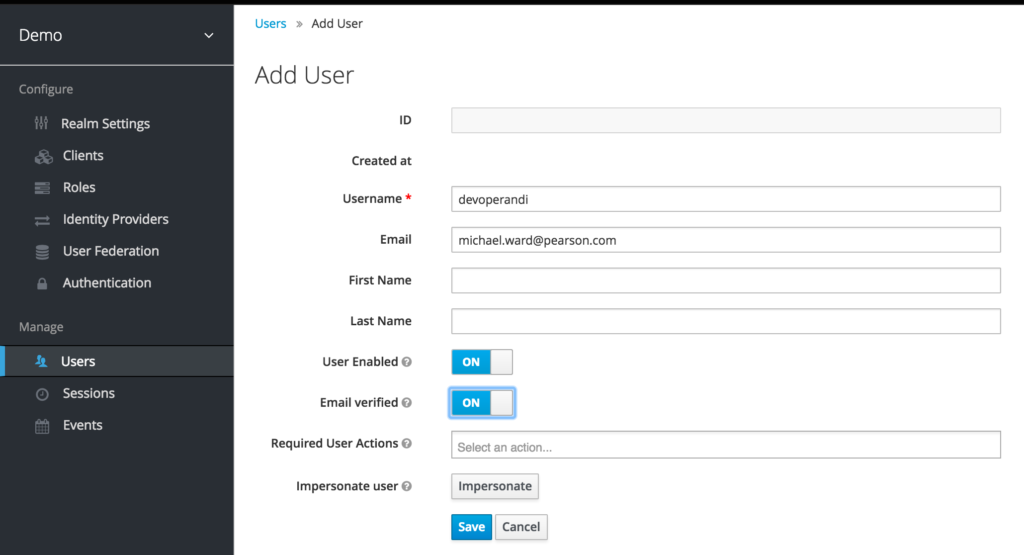
Notice how I have set the email when creating the user.
This is because I’ve set email in the oidc user claim in Kubernetes
- --oidc-username-claim=email
AND the following in the Apache server.
OIDCRemoteUserClaim email OIDCScope "openid email"
If you should choose to allow users to register with Keycloak I highly recommend you make email *required* if using this blog as a resource.
Apache Configuration:
First lets configure our Apache server or better yet just spin up a docker container.
To spin up a separate server do the following:
- mod_auth_openidc installed on apache server from here
- mod_proxy loaded
- mod_ssl loaded
- ‘USE_X_FORWARDED_HOST = True’ is added to /usr/lib/python2.7/site-packages/cloudinit/settings.py if using Python 2.7ish
- Configure auth_openidc.conf and place it at /etc/httpd/conf.d/auth_openidc.conf in on centos.
- Reference the Readme here for config values.
To spin up a container:
Run a docker container with environment variables set. This Readme briefly explains each environment var. And the following template can be copied from here.
<VirtualHost _default_:443>
SSLEngine on
SSLProxyEngine on
SSLProxyVerify ${SSLPROXYVERIFY}
SSLProxyCheckPeerCN ${SSLPROXYCHECKPEERCN}
SSLProxyCheckPeerName ${SSLPROXYCHECKPEERNAME}
SSLProxyCheckPeerExpire ${SSLPROXYCHECKPEEREXPIRE}
SSLProxyMachineCertificateFile ${SSLPROXYMACHINECERT}
SSLCertificateFile ${SSLCERT}
SSLCertificateKeyFile ${SSLKEY}
OIDCProviderMetadataURL ${OIDCPROVIDERMETADATAURL}
OIDCClientID ${OIDCCLIENTID}
OIDCClientSecret ${OIDCCLIENTSECRET}
OIDCCryptoPassphrase ${OIDCCRYPTOPASSPHRASE}
OIDCScrubRequestHeaders ${OIDCSCRUBREQUESTHEADERS}
OIDCRemoteUserClaim email
OIDCScope "openid email"
OIDCRedirectURI https://${REDIRECTDOMAIN}/redirect_uri
ServerName ${SERVERNAME}
ProxyPass / https://${SERVERNAME}/
<Location "/">
AuthType openid-connect
#Require claim sub:email
Require valid-user
RequestHeader set Authorization "Bearer %{HTTP_OIDC_ACCESS_TOKEN}e" env=HTTP_OIDC_ACCESS_TOKEN
LogLevel debug
</Location>
</VirtualHost>
Feel free to use the openidc.yaml as a starting point if deploying in Kubernetes.
Kubernetes API Server:
kube-apiserver.yaml
- --oidc-issuer-url=https://keycloak_domain/auth/realms/demo
- --oidc-client-id=kubernetes
- --oidc-ca-file=/path/to/ca.pem
- --oidc-username-claim=email
oidc-issuer-url
- substitute keycloak_domain for the ip or domain to your keycloak server
- substitute ‘demo’ for the keycloak realm you setup
oidc-client-id
- same client id as is set in Apache
oidc-ca
- this is a shared ca between kubernetes and keycloak
OK so congrats. You should now be able to hit the Kubernetes Swagger UI with Keycloak/OpenID Connect authentication
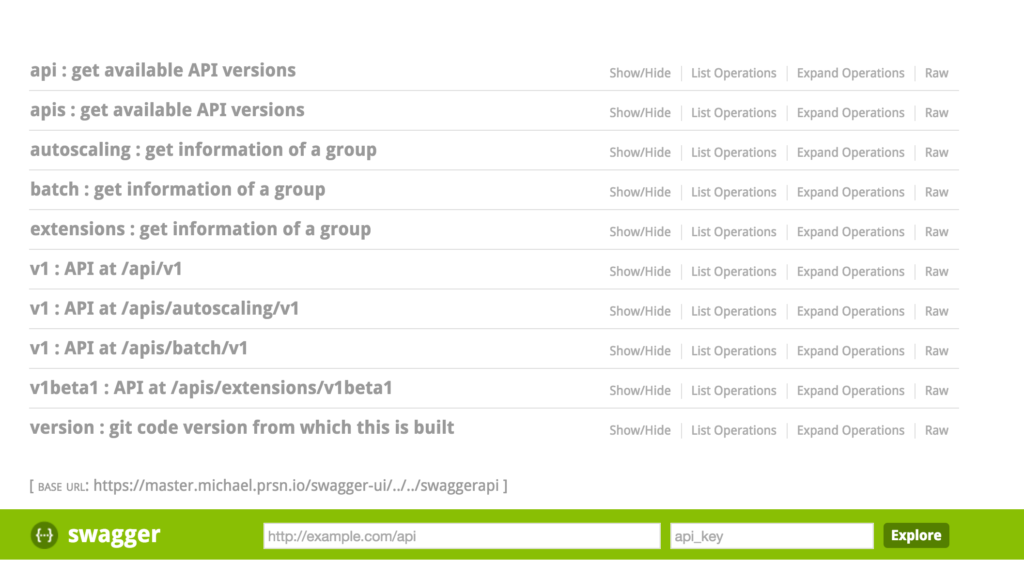
And you might be thinking to yourself about now, why the hell would I authenticate to Kubernetes through a web console?
Well remember how the kube-proxy can proxy requests through the Kubernetes API endpoint to various UIs like say Kube-UI. Tada. Now you can secure them properly.
Today all we have done is build authentication. Albeit pretty cool cause we have gotten ourselves out of statically managed Tokens, Certs or Basic Auth. But we haven’t factored in Authorization. In a future post, we’ll look at authorization and how to do it dynamically through webhooks.