Alright, finally ready to talk about some StackStorm in depth. In the first part of this post I discussed some depth around Kubernetes Thirdpartyresource and how excited we are to use them. If you haven’t read it I would go back and start there. I however breezed over the Event Drive Automation piece (IFTTT) involving StackStorm. I did this for two reasons: 1) I was terribly embarrassed by the code I had written and 2) It wasn’t anywhere near where it should be in order for people to play with it.
Now that we have a submittal to StackStorm st2contrib, I’m going to open this up to others. Granted its not in its final form. In fact there is a TON left to do but its working and we decided to get the community involved should you be interested.
But first lets answer the question that is probably weighing on many peoples mind. Why StackStorm? There are many other event driven automation systems. The quick answer is they quite simply won us over. But because I like bullet points. Here are a few:
- None of the competition were in a position to work with, support or develop a community around IFTTT integration with Kubernetes.
- StackStorm is an open frame work that you and I can contribute back to.
- Its built on OpenStack’s Mistral Workflow engine so while this is a startup like company, the foundation of what they are doing has been around for quite some time.
- Stable
- Open Source code base. (caveat: there are some components that are enterprise add-ons that are not)
- Damn their support is good. Let me just say, we are NOT enterprise customers of StackStorm and I personally haven’t had better support in my entire career. Their community slack channel is awesome. Their people are awesome. Major props on this. At risk of being accused of getting a kick-back, I’m a groupie, a fanboy. If leadership changes this (I’m looking at you Mr. Powell), I’m leaving. This is by far and away their single greatest asset. Don’t get me wrong, the tech is amazing but the people got us hooked.
For the record, I have zero affiliation with StackStorm. I just think they have something great going on.
As I mentioned in the first post, our first goal was to automate deployment of AWS RDS databases from the Kubernetes framework. We wanted to accomplish this because then we could provide a seamless way for our dev teams to deploy their own database with a Kubernetes config based on thirdpartyresource (currently in beta).
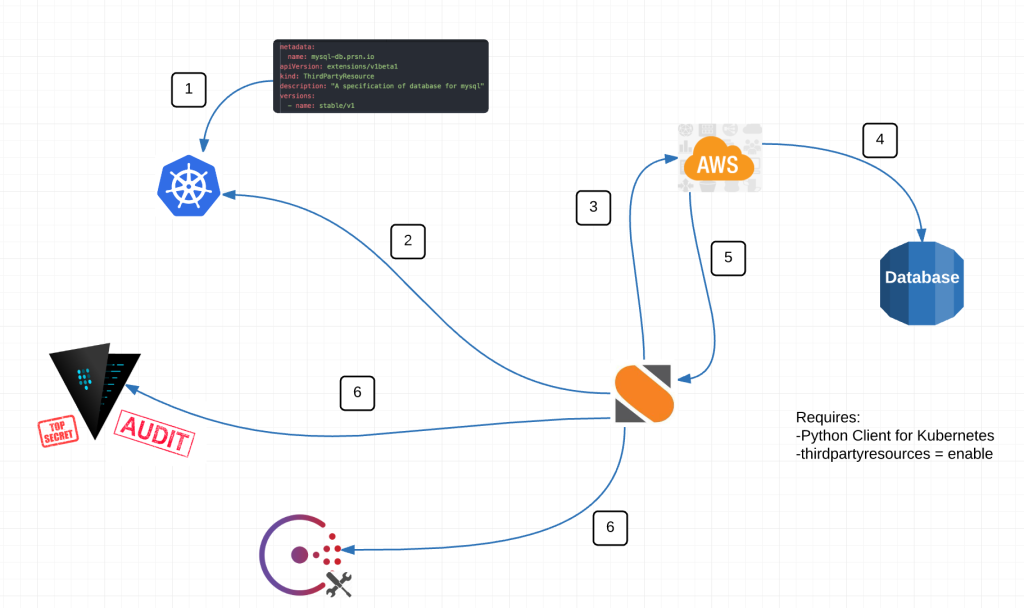
Here is a diagram of the magic:
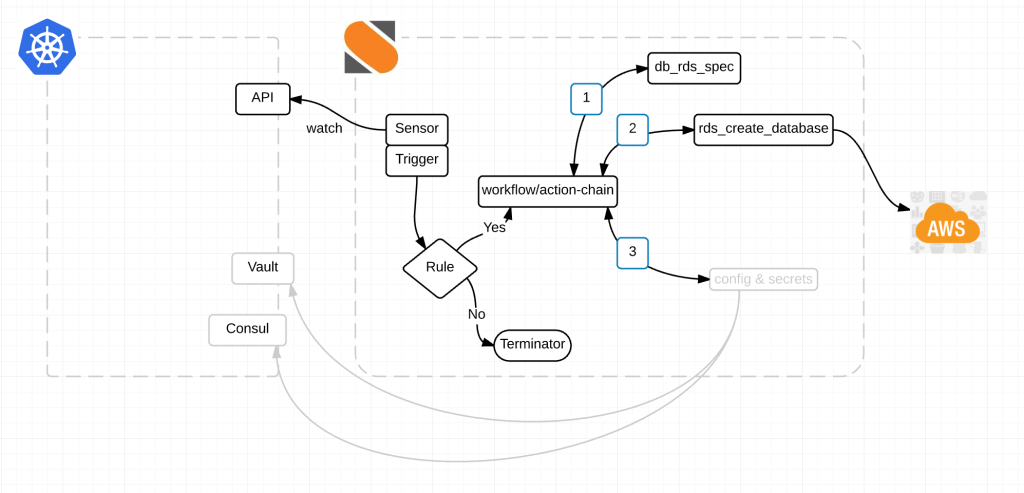
Alright here is what’s happening.
- We have a StackStorm Sensor watching the Kubernetes API endpoint at /apis/extensions/v1beta1/watch/thirdpartyresources for events. thirdpartyresource.py
- When a new event happens, the sensor picks it up and kicks off a trigger. Think of a trigger like a broadcast message within StackStorm.
- Rules listen to trigger types that I think of as channels. Kind of like a channel on the telly. A rule based on some criteria, decides whether or not to act on any given event. It either chooses to drop the event or to take action on it. rds_create_db.yaml
- An action-chain then performs a series of actions. Those actions can either fail or succeed and additional actions happen based on the result of the last. db_create_chain.yaml
- db_rds_spec munges the data of the event. Turns it into usable information.
- from there rds_create_database reaches out to AWS and creates an RDS database.
- And finally configuration information and secrets are passed back to Consul and Vault for use by the application(s) within Kubernetes. Notice how the action for Vault and Consul are grey. Its because its not done yet. We are working on it this sprint.
Link to the StackStorm Kubernetes Pack. Take a look at the Readme for information on how to get started.
Obviously this is just a start. We’ve literally just done one thing in creating a database but the possibilities are endless for integrations with Kubernetes.
I mentioned earlier the StackStorm guys are great. And I want to call a couple of them out. Manas Kelshikar, Lakshmi Kannan and Patrick Hoolboom. There are several others that have helped along the way but these three helped get this initial pack together.
The initial pack has been submitted as a pull request to StackStorm for acceptance into st2contrib. Once the pull request has been accepted to st2contrib, I would love it if more people in the Kubernetes community got involved and started contributing as well.
@devoperandi