I’ve been working on a little piece of software that determines Kubernetes DISA/STIG compliance. Written in Ansible, it prints out a report.html showing compliance of a given Kubernetes cluster. Super simple to run, just set KUBECONFIG as an environment variable.
Category: containers
Kubernetes and AWS considerations
AWS
- EC2 user-data file should be generic – Having to modify user-data can cause major issues. Prefer to offload runtime based config to something like Ansible.
- AWS VPC CNI for EKS is not required. Although its an interesting option, the choice to run an alternate CNI plugin is yours.
Kubernetes
- Applications with slow startup times, should have a lower scaling (HPA) threshold so they can scale quickly enough to meet load demands.
- Kubernetes clusters running multiple host sizes should ensure pods are tainted/tolerated to run on the correct hosts.
- If automation of cloud services via Kubernetes is “in the cards” make sure all the dependencies can also be automated.
- Example: I once automated the use of AWS ALBs, ELBs and Route53 DNS via Kubernetes. Eventually we chose to use Cloud Front as well but there is no automation for it via Kubernetes (at the time of this writing). This left us with maintaining cloud front manually or writing Terraform separately.
Language specific best practices:
NodeJS
- Nodejs applications require 1 CPU and 1.5 GB of RAM by default. Make sure any application running nodejs has QoS set to 1 CPU and 1.75 GB of RAM. Nodejs apps without this run the risk of killing themselves because they assume they have the default regardless of what is set for QoS. The alternative is to modify the default resource requirements of Nodejs but many do not recommend doing this.
- Nodejs applications more heavily utilize DNS to make requests as they don’t by default cache a DNS entry. This tends to cause a significant amount of load on Kubernetes DNS.
Java
- Many Java applications utilize off-heap memory. Ensure QoS memory allocation for a Java app accounts for off-heap memory use.
- Java 8 and older use the server CPU for determining how much CPU is available. It ignores the amount set by Docker. This can lead to crashing if the app attempts to consume more CPU than it is allowed.
- Java 9+ can properly detect the correct CPU allocated.
Kubernetes – Device Plugins (alpha)
Brief History
In March of 2017, I wrote about Opaque Integer Resources whereby specific hardware capabilities could be used in Kubernetes. Alpha in 1.5, it allowed for the potential to enable resource like Last Level Cache, GPUs and Many Integrated Core devices etc etc.
In Kubernetes 1.8, Opaque Integer Resources were replaced with Extended Resources. This was a great move as it migrated from a kubernetes.io/uri model to allow resources to be assigned to any domain outside kubernetes.io and thus simply extend the API with API aggregation.
Extended Resources are a phenomenal start to vastly expand opportunities around Kubernetes workloads but it still had the potential to require modifications to Kubernetes core in order to actually use a new resource. And this is where Device Plugins come in.
Requirements:
Kubernetes 1.8
DevicePlugins enabled in Kubelet
Device Plugins
Device Plugins is a common framework by which hardware devices for specific vendors can be plugged into Kubernetes.
Think of it this way:
Extended Resources = how to use a new resource Device Plugins = how vendors can advertise to and hook into Kubernetes without modifying Core
One of the first examples of Device Plugins in use is with Nvidia k8s-device-plugin. Which makes complete sense because Nvidia is leading an entire industry is various hardware arenas, GPU being just one of them.
How Device Plugins work
Device Plugins are/should be containers running in Kubernetes that provide access to a vendor (or enterprise) specific resource. The container advertises said resource to Kubelet via gRPC. Because this is hardware specific, it must be done on a per node basis. However a Daemonset can be deployed to cover a multitude of nodes for the same resource across multiple machines.
The Device Plugin has three parts:
Registration – plugin advertises itself to Kubelet over gPRC
ListandWatch – provides list of devices and/or modifies existing state of device on change including failures
Allocate – device specific instructions for Kubelet to make available to a container
At first glance this may seem rather simple but it should be noted that prior to Device Plugins, Kubelet specifically handled each device. Which is where hardware vendors had to contribute back to Kubernetes Core to provide net new hardware resources. With device plugin manager, this will be abstracted out and responsibility will lay on the vendor. Kubelet will then keep a socket open to ListandWatch for any changes in device state or list of devices.
Use of new devices through Extended Resources
Once a new Device Plugin is advertised to the cluster. It will be quite simple to use.
Now lets imagine we are using Nvidia’s GPU device plugin at nvidia.com/gpu
Here is how we allocate a gpu resource to a container.
apiVersion: v1
kind: Pod
metadata:
name: need-some-gpu-pod
spec:
containers:
- name: my-container-needing-gpu
image: myimage
resources:
requests:
cpu: 2
nvidia.com/gpu: 1
Gotchas
(At the time of this post)
Integers Only – this is common in Kubernetes but worth noting. 1 for gpu above can not be 0.5.
No Overallocation – Unlike Memory and CPU, devices can not be over allocated. So if Requests and Limits are specified, they must equal each other.
Resource Naming – I can’t confirm this but playing around with nvidia gpu I was unable to create multiple of the same device across multiple nodes.
Example:
I had difficulty advertising nvidia.com/gpu on node 2 once it was advertised on node one.
If correct, this would mean I would need to add nvidia.com/gpu-<node_name> or something of that measure to add the gpu device for multiple servers in a cluster. And also call out that specific device when assigning to the container requiring the resource. Now keep in mind, this is alpha so I would expect it to get modified rapidly but it is currently a limitation.
More info on Device Plugins
For a deeper review of the Device Plugin Manager
More on Extended Resources and Opaque Integer Resources
@devoperandi
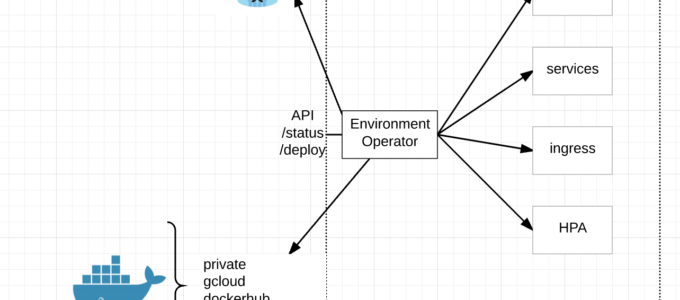
Open Source – Environment Operator
The day has finally come. Today we are announcing our open source project Environment Operator (EO).
Environment Operator is used throughout our project and has rapidly gained a name for itself as being well written and well thought out. Props go out to Simas Cepaitis, Cristian Radu and Ben Somogyi who have all contributed.
At its core, EO enables a seamless application deployment capability for a given environment/namespace within Kubernetes.
Benefits/Features:
- multi-cluster deployments
- audit trail
- status
- consistent definition of customer environments
- separate build from deploy
- minimizes risk and scope of impact
- simple abstraction from Kubernetes
- BYO CI/CD
- empowers our customers (dev teams)
- API interface
- multiple forms of authentication
- deploy through yaml config and API
- written in Go
- Docker Registries
Multi-Cluster Deployments – With EO running in each namespace and exposed via an API, CI/CD pipelines can simply call the API endpoint regardless of Kubernetes cluster and deploy new services.
API Interface – EO has its own API endpoint for deployments, status, logs and the like. This combined with a yaml config for its environment is a very powerful combination.
Audit Trail – EO provides an audit trail of all changes to the environment through its logging to stdout.
Status – EO provides a /status endpoint by which to understand the status of an environment or individual services within the environment with /status/${service}
Separate Build from Deploy – What we found was, while our CI/CD pipeline is quite robust it lacked real-time feedback and audit capabilities needed by our dev teams. Separating our build from deploy allowed us to add in these additional features, simplify its use and enabled our dev teams to bring their own familiar pipelines to our project.
Minimize Risk and Scope of impact – Because EO runs inside the Kubernetes cluster we could limit its capabilities through Kubernetes service accounts to only its namespace. This limits risk and impact to other dev teams running in the same cluster as well as requiring a dev to call and entirely wrong API endpoint in order to effect another environment. Further more, authentication is setup for each EO, so separation of concerns between environments can easily be made.
Simple Abstraction – Because EO is so simple to use, it has enabled our teams to get up and running much faster in Kubernetes. Very little prior knowledge is required, they can use their same pipelines by using a common DSL in our Jenkins plugin and get all the real-time information all from one place per environment.
BYO CI/CD – I think this is pretty self-explanatory but we have many dev teams at Pearson that already have their own CI/CD pipelines. They can continue using their pipeline or choose to use ours.
Empower our Dev teams – Ultimately EO is about empowering Dev teams to manage their own environments without requiring tons of prior knowledge to get started. Simply deploy EO and go.
Authentication – EO currently supports two different kinds of authentication. Token based which gets pulled from a Kubernetes secret or OAuth. We currently tie directly into Keycloak for auth.
Plugin (DSL) for Jenkins – Because most of our Dev teams run Jenkins, we wrote a plugin to hook directly into it. Other plugins could very easily be written.
Docker Registries – EO can connect to private, public, gcloud and docker hub registries.
As you can see, Environment Operator has a fair amount of capabilities built-in but we aren’t stopping there.
Near term objectives:
- Stateful sets
- Kubernetes Jobs
- Prometheus
Github:
https://github.com/pearsontechnology/environment-operator
https://github.com/pearsontechnology/environment-operator-jenkins-plugin
Let us know what you think!
@devoperandi
Kubernetes – PodPresets
Podpresets in Kubernetes are a cool new addition to container orchestration in v1.7 as an alpha capability. At first they seem relatively simple but when I began to realize their current AND potential value, I came up with all kinds of potential use cases.
Basically Podpresets inject configuration into pods for any pod using a specific Kubernetes label. So what does this mean? Have a damn good labeling strategy. This configuration can come in the form of:
- Environment variables
- Config Maps
- Secrets
- Volumes/Volumes Mounts
Everything in a PodPreset configuration will be appended to the pod spec unless there is a conflict, in which case the pod spec wins.
Benefits:
- Reusable config across anything with the same service type (datastores as an example)
- Simplify Pod Spec
- Pod author can simply include PodPreset through labels
Example Use Case: What IF data stores could be configured with environment variables. I know, wishful thinking….but we can work around this. Then we could setup a PodPreset for MySQL/MariaDB to expose port 3306, configure for InnoDB storage engine and other generic config for all MySQL servers that get provisioned on the cluster.
Generic MySQL Pod Spec:
apiVersion: v1
kind: Pod
metadata:
name: mysql
labels:
app: mysql-server
preset: mysql-db-preset
spec:
containers:
- name: mysql
image: mysql:8.0
command: ["mysqld"]
initContainers:
- name: init-mysql
image: initmysql
command: ['script.sh']
Now notice there is an init container in the pod spec. Thus no modification of the official MySQL image should be required.
The script executed in the init container could be written to templatize the MySQL my.ini file prior to starting mysqld. It may look something like this.
#!/bin/bash cat >/etc/mysql/my.ini <<EOF [mysqld] # Connection and Thread variables port = $MYSQL_DB_PORT socket = $SOCKET_FILE # Use mysqld.sock on Ubuntu, conflicts with AppArmor otherwise basedir = $MYSQL_BASE_DIR datadir = $MYSQL_DATA_DIR tmpdir = /tmp max_allowed_packet = 16M default_storage_engine = $MYSQL_ENGINE ... EOF
Corresponding PodPreset:
kind: PodPreset
apiVersion: settings.k8s.io/v1alpha1
metadata:
name: mysql-db-preset
namespace: somenamespace
spec:
selector:
matchLabels:
preset: mysql
env:
- name: MYSQL_DB_PORT
value: "3306"
- name: SOCKET_FILE
value: "/var/run/mysql.sock"
- name: MYSQL_DATA_DIR
value: "/data"
- name: MYSQL_ENGINE
value: "innodb"
This was a fairly simple example of how MySQL servers might be implemented using PodPresets but hopefully you can begin to see how PodPresets can abstract away much of the complex configuration.
More ideas –
Standardized Log configuration – Many large enterprises would like to have a logging standard. Say something simply like all logs in JSON and formatted as key:value pairs. So what if we simply included that as configuration via PodPresets?
Default Metrics – Default metrics per language depending on the monitoring platform used? Example: exposing a default set of metrics for Prometheus and just bake it in through config.
I see PodPresets being expanded rapidly in the future. Some possibilities might include:
- Integration with alternative Key/Value stores
- Our team runs Consul (Hashicorp) to share/coordinate config, DNS and Service Discovery between container and virtual machine resources. It would be awesome to not have to bake in envconsul or consul agent to our docker images.
- Configuration injection from Cloud Providers
- Secrets injection from alternate secrets management stores
- A very similar pattern for us with Vault as we use for Consul. One single Secrets/Cert Management store for container and virtual machine resources.
- Cert injection
- Init containers
- What if Init containers could be defined in PodPresets?
I’m sure there are a ton more ways PodPresets could be used. I look forward to seeing this progress as it matures.
@devoperandi
Kong API Gateway
Why an API gateway for micro services?
API Gateways can be an important part of the Micro Services / Serverless Architecture.
API gateways can assist with:
- managing multiple protocols
- working with an aggregator for web components across multiple backend micro services (backend for front-end)
- reducing the number of round trip requests
- managing auth between micro services
- TLS termination
- Rate Limiting
- Request Transformation
- IP blocking
- ID Correlation
- and many more…..
Kong Open Source API Gateway has been integrated into several areas of our platform.
Benefits:
- lightweight
- scales horizontally
- database backend only for config (unless basic auth is used)
- propagations happen quickly
- when a new configuration is pushed to the database, the other scaled kong containers get updated quickly
- full service API for configuration
- The API is far more robust than the UI
- supports some newer protocols like HTTP/2
- https://github.com/Mashape/kong/pull/2541
- Kong continues to work even when the database backend goes away
- Quite a few Authentication plugins are available for Kong
- ACLs can be utilized to assist with Authorization
Limitations for us (not necessarily you):
- Kong doesn’t have enough capabilities around metrics collection and audit compliance
- Its written in Lua (we have one guy with extensive skills in this area)
- Had to write several plugins to add functionality for requirements
We run Kong as containers that are quite small in resource consumption. As an example, the gateway for our documentation site consumes minimal CPU and 50MB of RAM and if I’m honest we could probably reduce it.
Kong is anticipated to fulfill a very large deployment in the near future for us as one of our prime customers (internal Pearson development team) is also adopting Kong.
Kong is capable of supporting both Postgres and Cassandra as storage backends. I’ve chosen Postgres because Cassandra seemed like overkill for our workloads but both work well.
Below is an example of a workflow for a micro service using Kong.
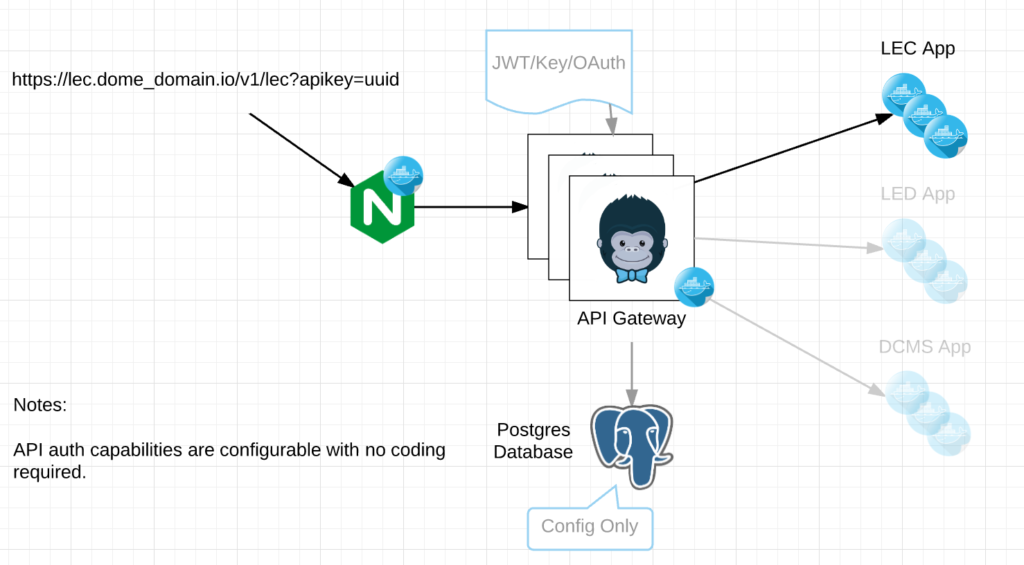
In the diagram above, the request contains the /v1/lec URI for routing to the correct micro service from. In line with this request, Kong can trigger an OAuth workflow or even choose not to authenticate for specific URIs like /health or /status if need be. We use one type of authentication for webhooks and another for users as an example.
In the very near future we will be open sourcing a few plugins for Kong for things we felt were missing.
- rewrite rules plugin
- https redirect plugin (think someone else also has one)
- dynamic access control plugin
all written by Jeremy Darling on our team.
We deploy Kong along side the rest of our container applications and scale them as any other micro service. Configuration is completed via curl commands to the Admin API.
The Admin API properly responds with both a http code (200 OK) and a json object containing the result of the call if its a POST request.
Automation has been put in place to enable us to configure Kong and completely rebuild the API Gateway layer in the event of a DR scenario. Consider this as our “the database went down, backups are corrupt, what do we do now?” scenario.
We have even taken it so far as to wrap it into a Universal API so Kong gateways can be configured across multiple geographically disperse regions that serve the same micro services while keeping the Kong databases separate and local to their region.
In the end, we have chosen Kong because it has the right architecture to scale, has a good number of capabilities one would expect in an API Gateway, it sits on Nginx which is a well known stable proxy technology, its easy to consume, is api driven and flexible yet small enough in size that we can choose different implementations depending on the requirements of the application stack.
Example Postgres Kubernetes config
apiVersion: v1
kind: Service
metadata:
name: postgres
spec:
ports:
- name: pgsql
port: 5432
targetPort: 5432
protocol: TCP
selector:
app: postgres
---
apiVersion: v1
kind: ReplicationController
metadata:
name: postgres
spec:
replicas: 1
template:
metadata:
labels:
app: postgres
spec:
containers:
- name: postgres
image: postgres:9.4
env:
- name: POSTGRES_USER
value: kong
- name: POSTGRES_PASSWORD
value: kong
- name: POSTGRES_DB
value: kong
- name: PGDATA
value: /var/lib/postgresql/data/pgdata
ports:
- containerPort: 5432
volumeMounts:
- mountPath: /var/lib/postgresql/data
name: pg-data
volumes:
- name: pg-data
emptyDir: {}
Kubernetes Kong config for Postgres
apiVersion: v1
kind: Service
metadata:
name: kong-proxy
spec:
ports:
- name: kong-proxy
port: 8000
targetPort: 8000
protocol: TCP
- name: kong-proxy-ssl
port: 8443
targetPort: 8443
protocol: TCP
selector:
app: kong
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: kong-deployment
spec:
replicas: 1
template:
metadata:
labels:
name: kong-deployment
app: kong
spec:
containers:
- name: kong
image: kong
env:
- name: KONG_PG_PASSWORD
value: kong
- name: KONG_PG_HOST
value: postgres.default.svc.cluster.local
- name: KONG_HOST_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
command: [ "/bin/sh", "-c", "KONG_CLUSTER_ADVERTISE=$(KONG_HOST_IP):7946 KONG_NGINX_DAEMON='off' kong start" ]
ports:
- name: admin
containerPort: 8001
protocol: TCP
- name: proxy
containerPort: 8000
protocol: TCP
- name: proxy-ssl
containerPort: 8443
protocol: TCP
- name: surf-tcp
containerPort: 7946
protocol: TCP
- name: surf-udp
containerPort: 7946
protocol: UDP
If you look at the configs above, you’ll notice it does not expose Kong externally. This is because we use Ingress Controllers so here is an ingress example.
Ingress Config example:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
labels:
name: kong
name: kong
namespace: ***my-namespace***
spec:
rules:
- host: ***some_domain_reference***
http:
paths:
- backend:
serviceName: kong
servicePort: 8000
path: /
status:
loadBalancer: {}
Docker container – Kong
https://hub.docker.com/_/kong/
Kubernetes Deployment for Kong
https://github.com/Mashape/kong-dist-kubernetes
@devoperandi
Open Source – Bitesize-controllers
The Bitesize team has been working with the nginx-controller for quite some time. Over that time we have modified, updated, coerced it to our will and its high time we open source this thing.
First I want to call out the engineers that have contributed to this controller and make sure they get the recognition they deserve. Congrats to Martin Devlin and Simas Cepaitis with encores Jeremy Darling and Thilina Piyasundara.
It takes the normal nginx-controller and bakes in Vault (Hashipcorp) integration.
Basic steps are:
- push TLS cert into Vault
- Create Ingress with
-
metadata: name: example namespace: some-namespace labels: ssl: true
-
- Nginx will get the new Ingress, pull the TLS cert from Vault and reload the nginx config.
I’ve written about Vault at various times. The latest is here.
In the future we intend add far more granularity to and even use this on a per project/namespace basis.
So here it is – Bitesize Controllers
And the Readme
We have plans to add more controllers in the future so stay tuned.
deployment pipeline options for Kubernetes
In the last several months various deployment (CI/CD) pipelines have cropped up within the Kubernetes community and our team also released one at KubeCon Seattle 2016. As a result I’ve been asked on a couple different occasions why we built our own. So here is my take.
We began this endeavor sometime late 2015. You can see our initial commit is on Feb 27th, 2016 to Github. But if you look closer, you will notice its a very large commit. Some 806 changes. This is because we began this project quite a bit before this time. So what does this mean? Nothing other than we weren’t aware of any other CD pipeline projects at the time and we needed one. So we took it upon ourselves to create one. You can see my slides at KubeCon London March 2016 where I talk about it a fair amount.
My goal of this blog is not to persuade you of one particular CD pipeline or another. I simply don’t care beyond the fact that contributions to Pearson’s CD pipeline would mean we can make it better faster. Beyond this we get nothing out of it.
Release it as Open Source –
We chose to release our project as open source for the community to consume at Kubecon Seattle 2016. To share our thoughts and experience on the topic, offer another option for the community to consume and provide insight to how we prefer to build/deploy/test/manage our environments.
Is it perfect? No.
Is it great? Yes, in my opinion its pretty great.
Does it have its own pros AND cons? hell yes it does.
Lets dig in, shall we?
There are two projects I’m aware of that claim many of the same capabilities. It is NOT my duty to explain all of them in detail but rather point out what I see as pros/cons/differences (which often correlate to different modes of thought) between them.
I will be happy to modify this blog post if/when I agree with a particular argument so feel free to add comments.
Fabric8 CD Pipeline – (Fabric8)
https://fabric8.io/guide/cdelivery.html
The Fabric8 CD pipeline was purpose built for Kubernetes/OpenShift. It has some deeper integrations with external components that are primarily RedHat affiliated. Much of the documentation focuses on Java based platforms even though they remark they can integrate with many other languages.
Kubernetes/OpenShift
Capable of working out of the box with Kubernetes and OpenShift. My understanding is you can set this as a FABRIC8_PROFILE to enable one or the other.
Java/JBoss/RedHat as a Focus point
While they mention being able to work with multiple languages, their focus is very much Java. They have some deep integrations with Apache Camel and other tools around Java including JBoss Fuse.
Artifact Repository
The CD pipeline for Fabric8 requires Nexus, an artifact repository.
Gogs or Github
Gogs is required for on-prem git repository hosting. I’m not entirely sure why Gogs would matter if simply accessing a git repo but apparently it does. Or there is integration with github.
Code Quality
Based on the documentation Fabric8 appears to require SonarType for use around code quality. This is especially important if you are running a Java project as Fabric8 automatically recognizes and attempts to integrate them. SonarType can support a variety of languages based on your use-case.
Pipeline Librarys
Fabric8 has a list of libraries for reusable bits of code to build your pipeline from. https://github.com/fabric8io/fabric8-jenkinsfile-library. Unfortunately these libraries tend to have some requirements around SonarType and the like.
Multi-Tenant
I’m not entirely sure as of yet.
Documentation
Fabric8’s documentation is great but very focused on Java based applications. Very few examples include any other languages.
Pearson CD Pipeline – (Pearson)
https://github.com/pearsontechnology/deployment-pipeline-jenkins-plugin
Kubernetes Only
Pure Kubernetes integration. No OpenShift.
Repository Integration
git. Any git, anywhere, via ssh key.
Language agnostic
The pipeline is entirely agnostic to language or build tools. This CI/CD platform does not specify any deep integrations into other services. If you want it, specify the package desired through the yaml config files and use it. Pearson’s CD pipeline isn’t specific to any particular language because we have 400+ completely separate development teams who need to work with it.
Artifact Repository
The Pearson CD pipeline does not specify any particular Artifact repo. It does however use a local aptly repo for caching deb packages. However nothing prevents artifacts from being shipped off to anywhere you like through the build process.
Ubuntu centric (currently)
Currently the CD pipeline is very much Ubuntu centric. The project has a large desire to integrate with Alpine and other base images but we simply aren’t there yet. This would be an excellent time to ask our community for help. please?
Opinionated
Pearson’s CD pipeline is opinionated about how and the order in which build/test/deploy happens. The tools used to perform build and test however are up to you. This gives greater flexibility but places the onus on the team around their choice of build/test tools.
Code Quality
The Pearson CD pipeline performs everything as code. What this is means is all of your tests should exist as code in a repository. Then simply point Jenkins to that repo and let it rip. The pipeline will handle the rest including spinning off the necessary number of slaves to do the job.
Ease of Use
Pearson’s CD pipeline is simple once the components are understood. Configuration code is reduced to a minimum.
Scalability
The CD pipeline will automatically spin up Jenkins slaves for various work requirements. It doesn’t matter if there are 1 or 50 microservices, build/test/deploy is relatively fast.
Tenancy
Pearson’s CD pipeline is intended to be used as a pipeline per project. Or better put, a pipeline per development team as each Jenkins pipeline can manage multiple Kubernetes namespaces. Pearson divides dev,stg,prd environments by namespace.
Documentation
Well lets just say Pearson’s documentation on this subject matter are currently lacking. There are plenty of items we need to add and it will be coming soon.
Final Thoughts:
Fabric8 deployment pipeline
The plugin the fabric8 team have built for integrating with Kubernetes/OpenShift is awesome. In fact the Pearson deployment pipeline intends to take advantage of some of their work. Hence the greatness of the open source community. If you have used Jenkinsfile, this will feel familiar to you. The Fabric8 plugin is focused on what tools should be used (ie SonarType, Nexus, Gogs, Apache Camel, Jboss Fuse). This could be explained away as having deeper integration allowing for a seamless integration but I would argue that most of these have APIs and its not difficult to make a call out which would allow for a tool agnostic approach. They also have a very high degree of focus on Java applications which doesn’t lend itself to the rest of the dev ecosystem. As I mentioned above, they do state they can integrate with other languages but I’ve been unable to find good examples of this in documentation.
Note: I was unable to find documentation on how the Fabric8 deployment pipeline scales. If someone has this information readily available I would love to read/hear about it. Its quite possible I just missed it.
Provided Jenkinsfile is a known entity, Java centric is the norm and you already integrate with many of the tools Fabric8 provides, this is probably a great fit for your team. If you need to have control over the CI/CD process, Fabric8 could be a good fit for you.
Pearson deployment pipeline
This is an early open source project. There are limitations around Ubuntu which we intend to alleviate. We simply haven’t had the demand from our customers to prioritize it yet. **Plug the community getting involved here***. Pearson’s deployment pipeline is very flexible from the sense of what tools it can integrate with yet more deterministic as to how the CI/CD process should work. There is no limitation on language. The Pearson deployment pipeline is easy to get started with and highly scalable. Jenkins will simply scale the number of slaves it needs to perform. Because the deployment pipeline abstracts away much of the CI/CD process, the yaml configuration will not be familiar at first.
If you don’t know Jenkins and you really don’t want to know the depths of Jenkins, Pearson’s pipeline tool might be a good place to start. Its simple 3 yaml config files will reduce the amount of configuration you need to get started. I would posit it will be half as many lines of config to create your pipeline.
The Pearson Deployment Pipeline project needs better examples/templates on how to work with various languages
Note:
Please remember, this blog is at a single point in time. Both projects are moving, evolving and hopefully shaping the way we think about pipelines in a container world.
Key Considerations:
Fabric8
Integrates well with OpenShift and Kubernetes
Tight integrations with other tools like SonarType, Camel and ActiveMQ, Gog etc etc
Less focus on how the CI/CD pipeline should work
Java centric
Requires other Fabric8 projects to get full utility from it
Tenancy – I’m not entirely sure. I probably just missed this in the documentation.
Pearson
Kubernetes Only
All purpose CD pipeline
Language Agnostic
More opinionated about the build/test/deploy process
Highly Scalable
Tenant per dev team/project
Easy transition for developers to move between dev teams
More onus on teams to create their build artifacts
KubeCon Seattle Video
Finally posting this after my speaking engagement at KubeCon_Seattle in November 2016. Thanks to all that came. My hope is releasing our Deployment Pipeline will help the Kubernetes community build an ecosystem of open source CI/CD pipelines to support an awesome platform.
Below the video are links to the various open source projects we have created which are in the last slide of the Conference deck.
Link to the Deployment Pipeline:
https://github.com/pearsontechnology/deployment-pipeline-jenkins-plugin
Vault SSL Integration:
https://github.com/devlinmr/contrib/tree/master/ingress/controllers/nginx-alpha-ssl
Kubernetes Tests:
https://github.com/pearsontechnology/kubernetes-tests
StackStorm Integrations:
https://github.com/pearsontechnology/st2contrib
Authz Webhook:
https://github.com/pearsontechnology/bitesize-authz-webhook
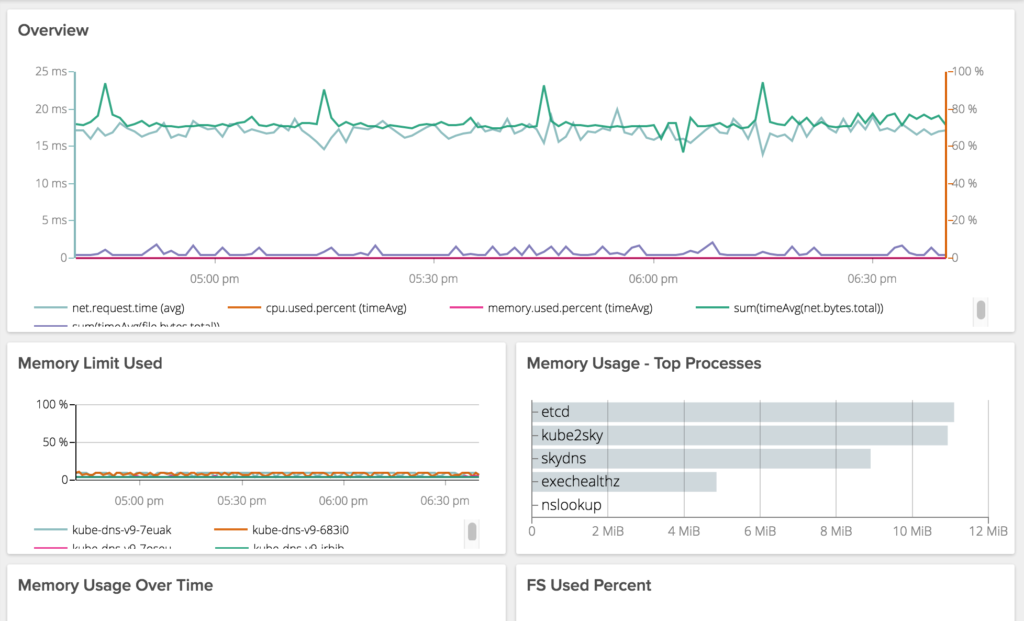
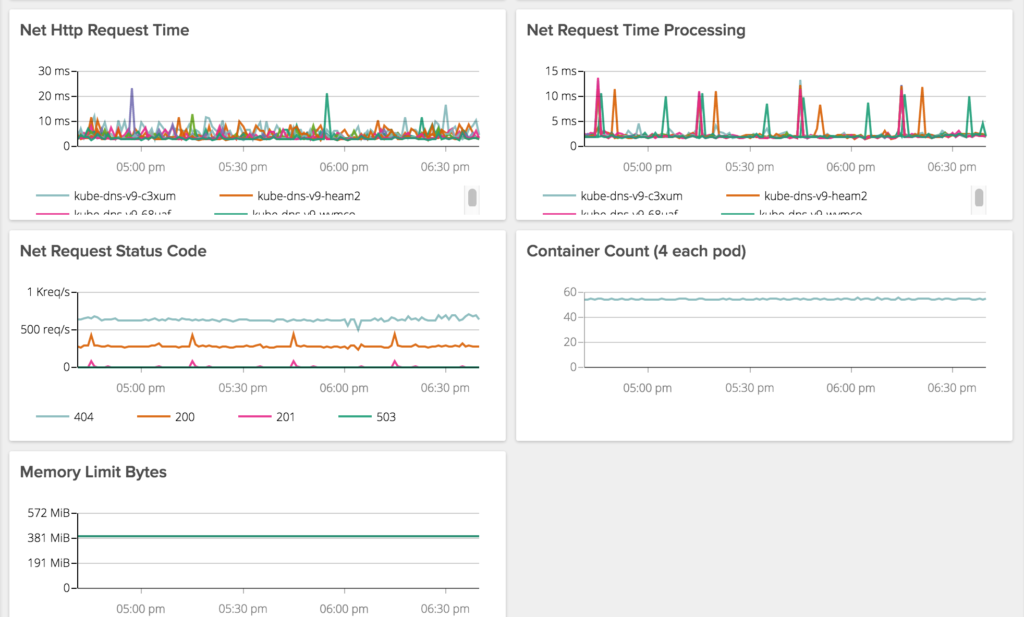
Kube-DNS – a little tuning
We recently upgraded Kube-dns.
gcr.io/google_containers/kubedns-amd64:1.6 gcr.io/google_containers/kube-dnsmasq-amd64:1.3
Having used SkyDNS up to this point, we ran into some unexpected performance issues. In particular we were seeing pretty exaggerated response times from kube-dns when making requests it is not authoritative on (i.e. not cluster.local).
Fortunately this was on a cluster not yet serving any production customers.
It took several hours of troubleshooting and getting a lot more familiar with our new DNS and Dnsmasq, in particular the various knobs we could turn but what hinted us off to our solution was the following issue.
https://github.com/kubernetes/kubernetes/issues/27679
** Update
Adding the following line to our “- args” config under gcr.io/google_containers/kubednsmasq-amd64:1.3 did the trick and significantly improved dns performance.
- --server=/cluster.local/127.0.0.1#10053 - --resolv-file=/etc/resolv.conf.pods
By adding the second entry we ensure requests only go upstream from kube-dns instead of back to the host level resolver.
/etc/resolv.conf.pods points only to external dns, in our case, AWS DNS for our VPC which is always %.%.%.2 for whatever your VPC IP range is.
** End Update
In either case, we have significantly improved performance on DNS lookups and are excited to see how our new DNS performs under load.
Final thoughts:
Whether tuning for performance or not realizing your cluster requires a bit more than 200Mi RAM and 1/10 of a CPU, its quite easy to overlook kube-dns as a potential performance bottleneck.
We have a saying on the team, if its slow, check dns. If it looks good, check it again. And if it still looks good, have someone else check it. Then move on to other things.
Kube-dns has bit us so many times, we have a dashboard to monitor and alert just on it. These are old screen caps from SkyDNS but you get the point.