First off. All credit for this goes to my friend Simas. I’m simply relaying what he has accomplished because it would be a shame if others didn’t benefit from his expertise. He is truly talented in this space and provides simple yet elegant designs that just work.
Coming into my current position we have 400+ development teams. Virtually all of which are managing their own build pipelines. This requires significant time and effort to manage, develop and automate. Each team designates their own developer on a rotating basis, or worse, completely dedicates a dev to make sure the build process goes smoothly.
What we found when looking across these teams was they were all basically doing the same thing. Sometimes using a different build server, automating using a different scripting language or running in a different code repo but all in all, its the same basic process with the same basic principles. And because we have so many dev teams, we were bound to run into enough teams developing in a particular language that it would make sense to standardize their process so multiple teams could take advantage of it. This combined with the power of docker images and we have a win/win situation.
So let me define what I mean by “build process” just so we can narrow the scope a bit. Build process – The process of building application(s) code using a common build platform. This is our first step in a complete CI/CD workflow.
So why haven’t we finished it already? Along with the Dev teams we have quite a few other engineering teams involved including QA/Performance/CISO etc etc and we haven’t finished laying out how all those teams will work together in the pipeline.
We have questions like:
Do QA/Perf/Security engineers all have access to multiple kubernetes namespaces or do they have their own project area and provide a set of endpoints and services which can be called to utilize their capabilities?
Do we mock cross-functional services in each namespace or provide endpoints to be accessed from anywhere?
What about continuous system/integration testing?
Continuous performance testing? How do we do this without adversely affecting our dev efforts?
Those are just a few of the questions we are working through. We have tons of them. Needless to say, we started with the build process.
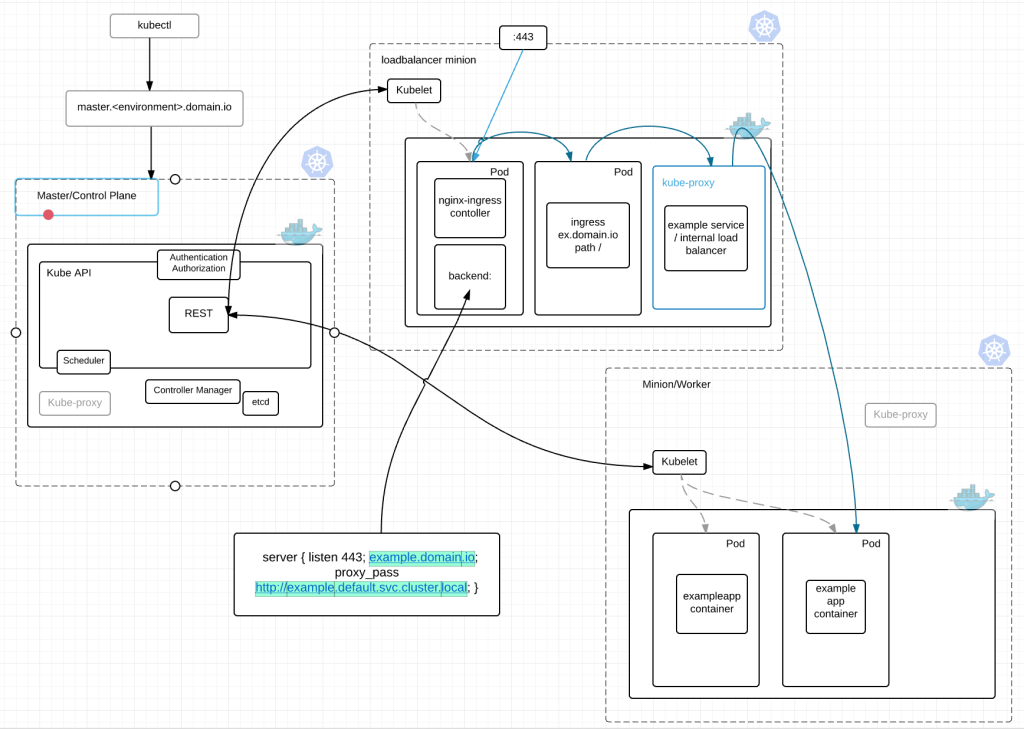
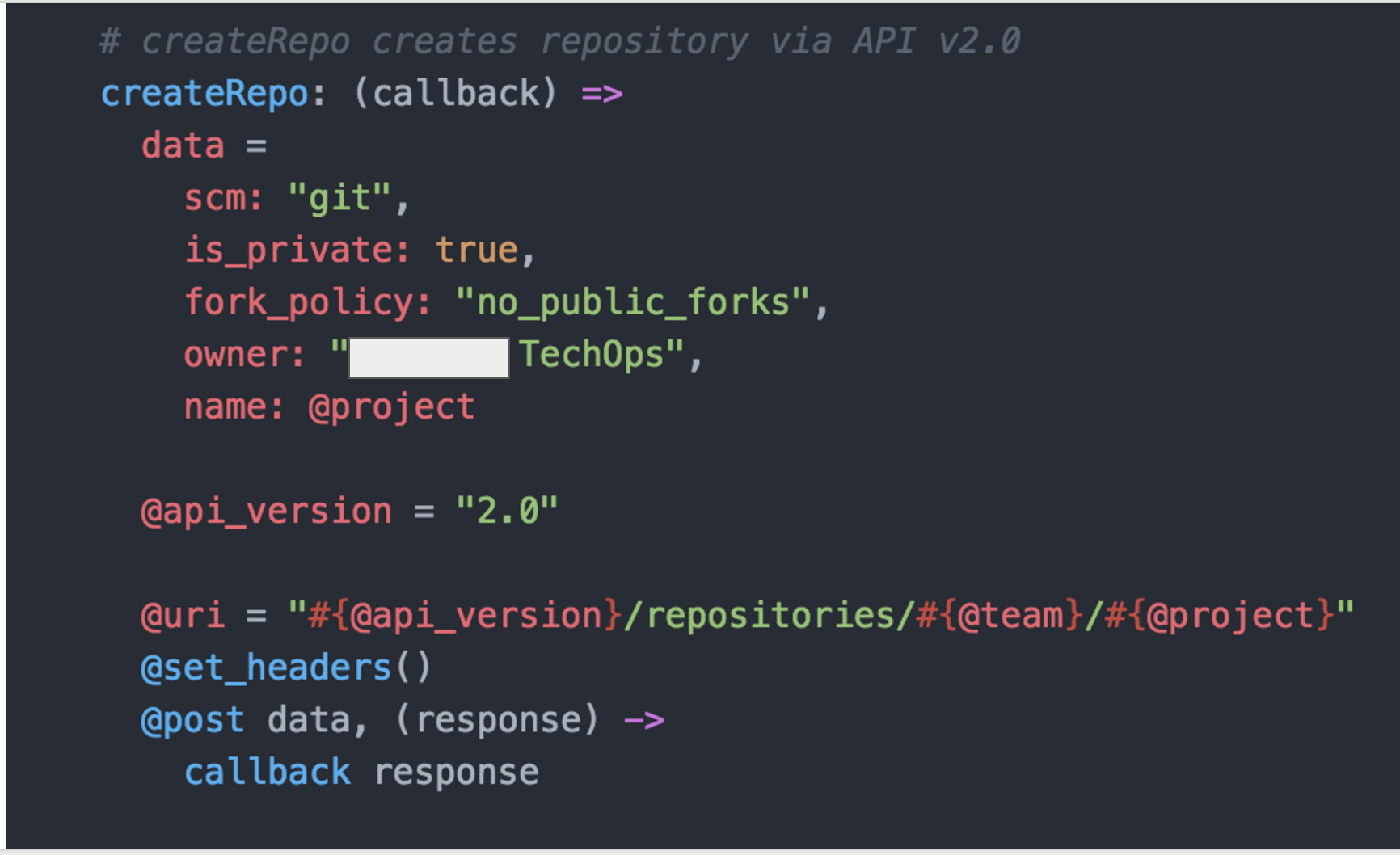
We create Docker images for each and every Java/NodeJS/Go/Ruby/language_of_the_month our developers choose. These images are very much standardized. Allowing for built-in, centrally managed, monitored, secure containers that deploy in very short periods of time. The only deltas are the packages for the actual application. We build those in deb packages and standardize the install process, directory locations, version per language type etc etc.
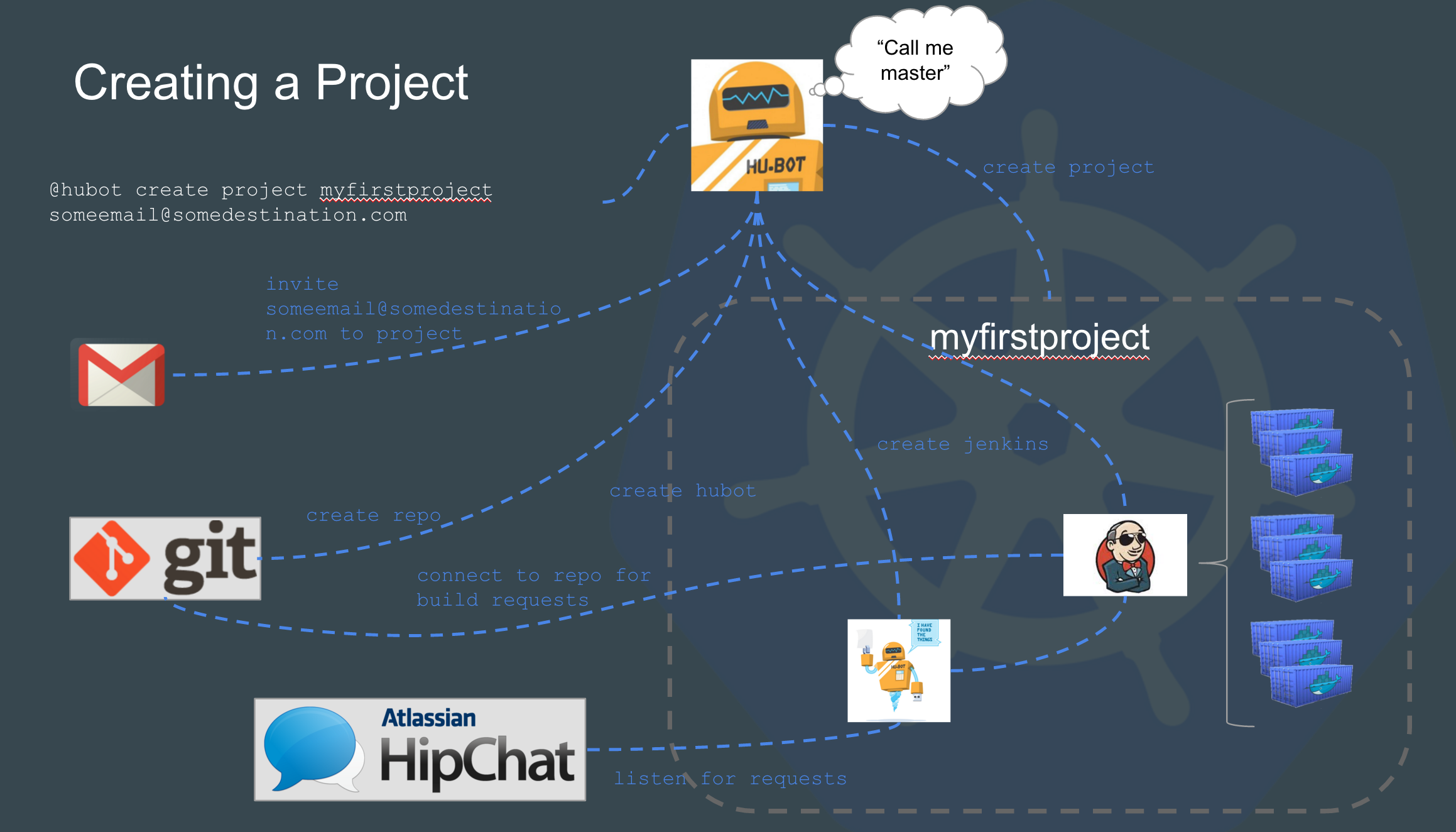
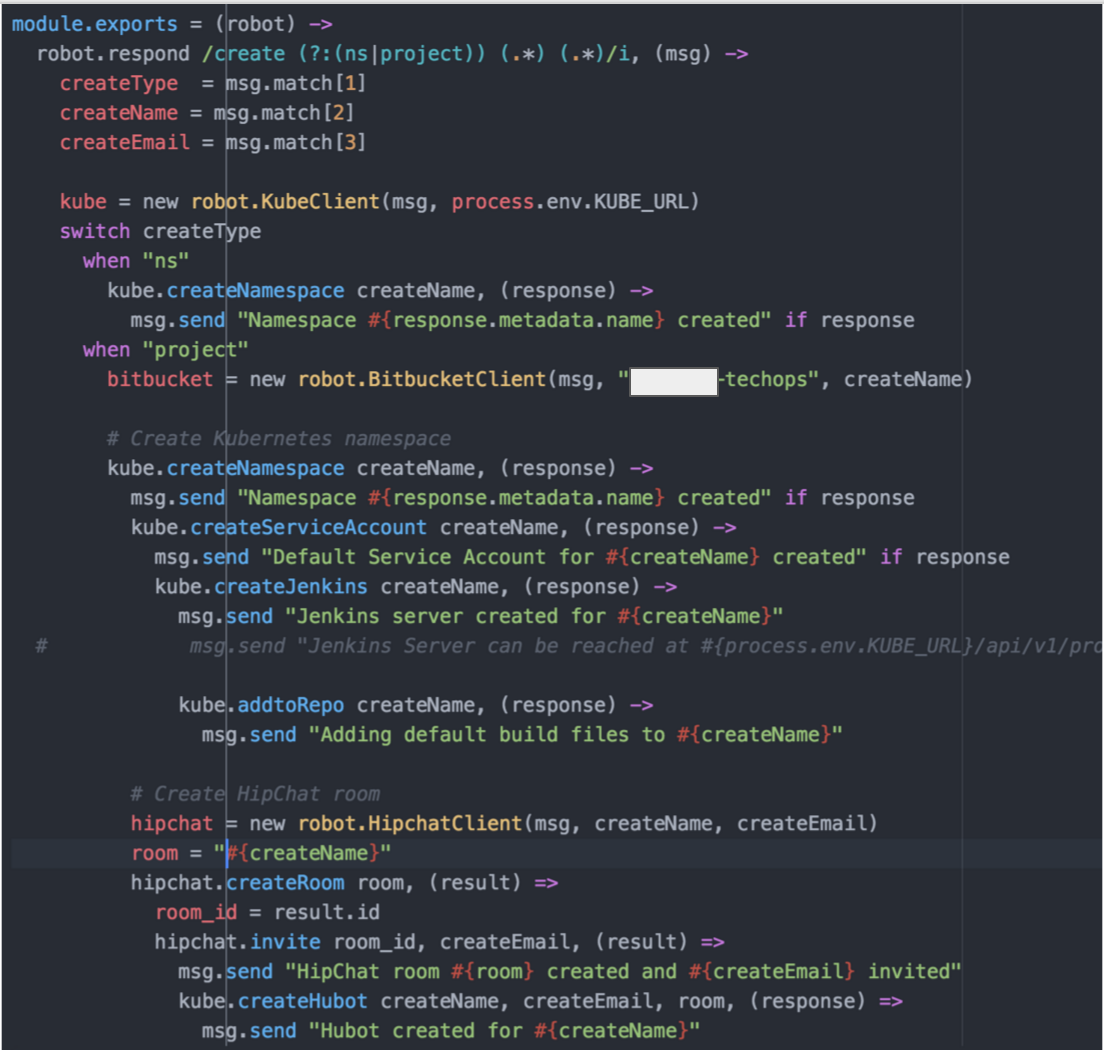
Dev teams get their own namespace in Kubernetes. In fact, in most cases they get three. Dev, Stage and Prod. For the purpose of this conversation every dev team is developing an application stack which could consist of 1 to many micro services. Every namespace has its own Hubot and its own Jenkins build server which is completely vanilla to start with.
See Integrating Hubot and Kubernetes for more info on Hubot.
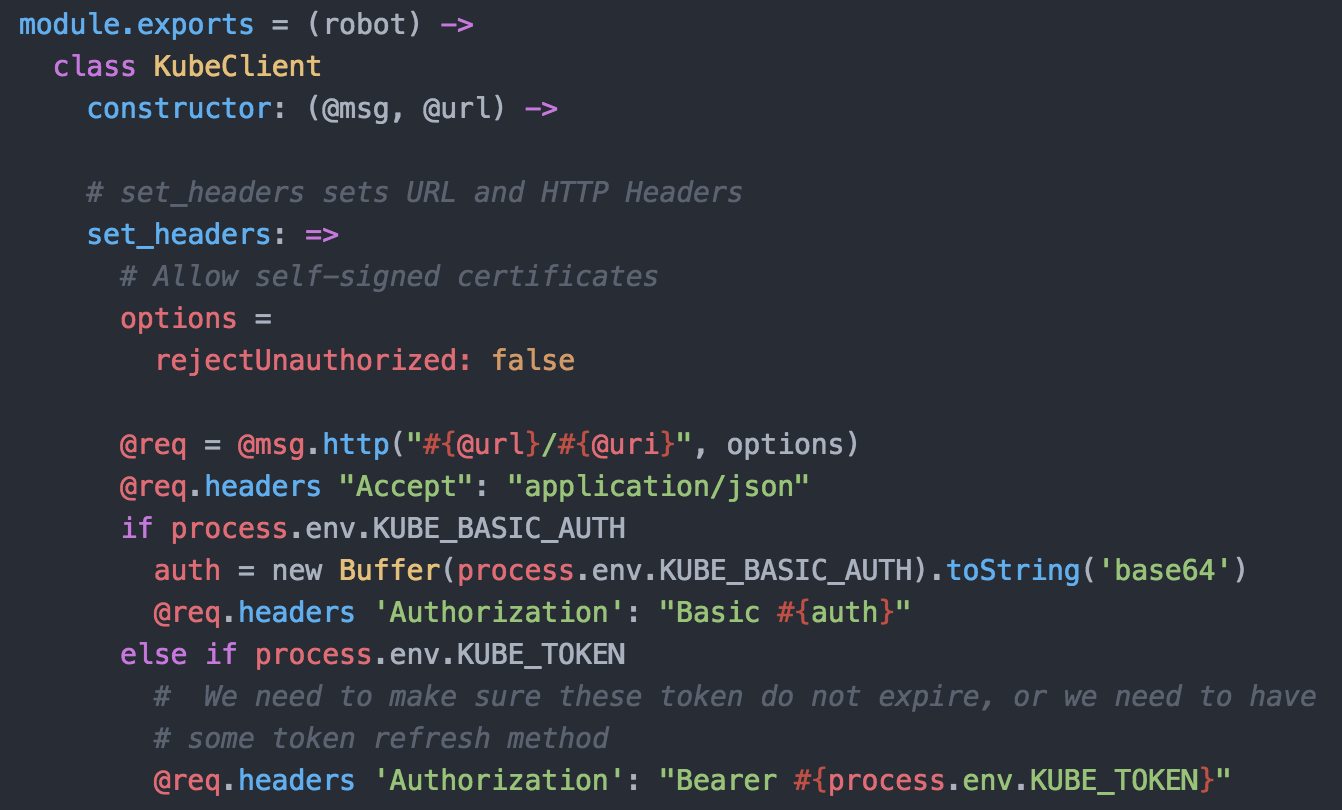
Each Jenkins build server connects to at least two repositories. A standard jenkins job repo that consists of all the standardized builds for each language and the application code repositories for the applications. EVERY Jenkins server connects to the same jenkins job repo. Jenkins polls each repo for changes every X minutes depending on the requirements of the team. We thought about web hooks to notify Jenkins when a new build is needed but chose to poll from Jenkins instead. Primarily because we treat every external resource as if it has gremlins and we didn’t want to deal with firewalls. We’ve been looking at options to replace this but haven’t settled on anything at this point.
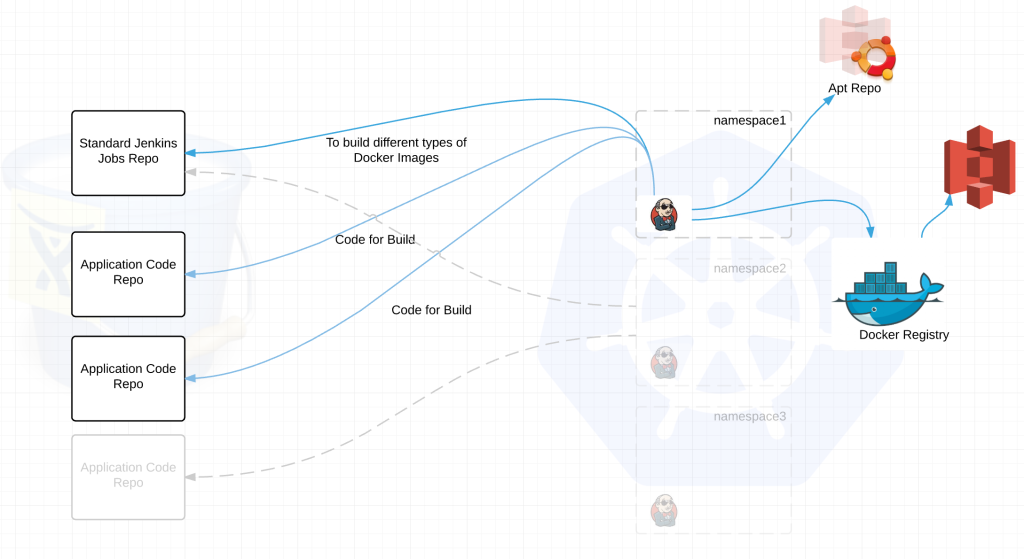
jenkins job repo –
- all the possible standardized build jobs
- dockerfiles for building base images – ie java,nodejs,ruby etc etc
- metadata on communicating with the local hubot
- sets up kubectl for its namespace
application code repo –
- Contains application code
- Contains a default.json file
default.json is key to the success of the build process.
It has three primary functions:
- Informs Jenkins what type of build it should be setup for. Ex. If XYZ team writes code in Java and NodeJS, it tells Jenkins to configure itself for those build types. This way we aren’t configuring every Jenkins server for build artifacts it will never build.
- It tells Jenkins meta-data about the application like application name, version, namespace(s) to deploy to, min/max number of containers to deploy, associated kubernetes services etc etc
- Provides Jenkins various build commands and artifacts particular to the application
Here is a very simple example of what that default.json might look like.
{
"namespace": "someproject",
"application": {
"name": "sample-application",
"type": "http_html",
"version": "3.x.x"
},
"build": {
"system_setup": {
"buildfacts": [ // Configure the Jenkins server
"java",
"nodejs"
]
},
"build_steps": [
{
"shell": "some shell commands"
},
{
"gradle": {
"useWrapper": true,
"tasks": "clean build -Ddeployment.target=???"
}
}
]
},
"build_command": "some command to execute the build",
"artifacts": "target/",
"services": [
{
"name": "sample-service",
"external_url": "www.sample-service.com",
"application": "someproject/sample-application",
"instances": {
"min": 2,
"max": 5
}
}
]
}
Ok now for a little more complexity:
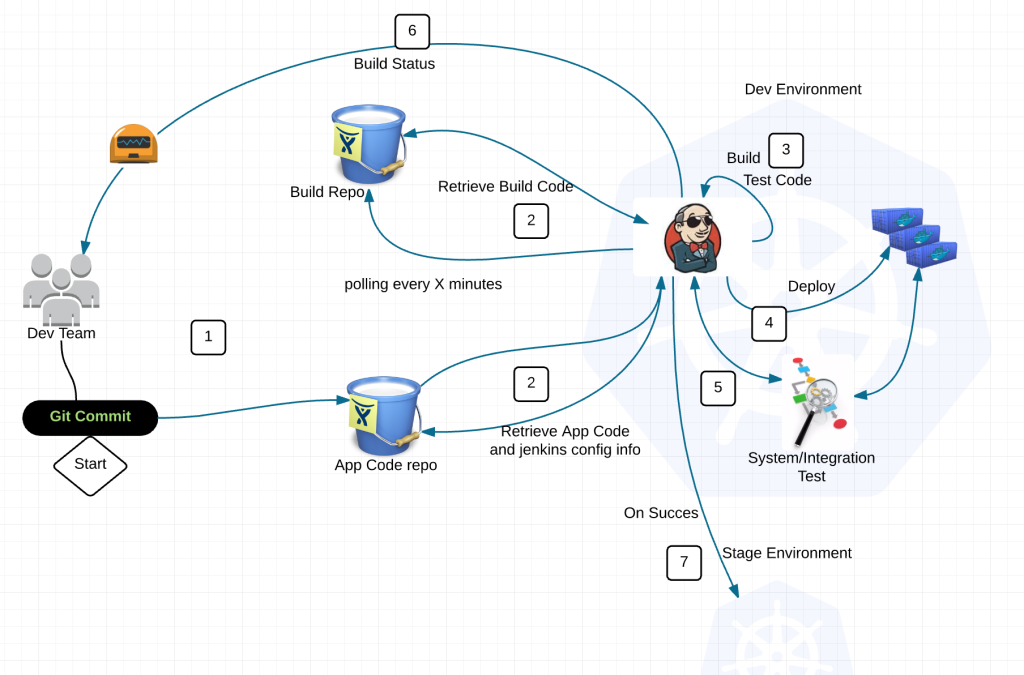
So what just happened?
1) Dev commits code to application repository
2) Jenkins polls the jenkins build repo and application repositories for changes
3) If there is a new standard build image (say for Java), jenkins will build the latest version of the application with this image and push the image to the docker registry with a specialized tag. Then notify Dev team of the change to provide feedback through hubot.
When there is a version change in the application code repository Jenkins runs typical local tests, builds deb package, ships it to apt repository, then builds a docker image combining a standardized image from the jenkins build repo with the deb package for the application and pushes the image to the Docker registry.
4) Deploy application into namespace with preconfigured kubectl client
5) Execute system/integration tests
6) Feedback loop to Dev team through Hubot
7) Rinse and repeat into Staging/Prod on success
Now you are probably thinking, what about all those extra libraries that some applications may need but other do not.
Answer: If its not a common library, it goes in the application build.
All in all this is a pretty typical workflow. And for the most part you are absolutely correct. So what value do we get by separating the standard/base build images and placing it into its own repository?
- App Eng develops standard images for each language and bakes in security/compliance/regulatory concerns
- Separation of concerns – Devs write code, System/App eng handles the rest including automated feedback loops
- Security Guarantee – Baked in security, compliance and regulatory requirements ensuring consistency across the platform
- Devs spend more time doing what they do best
- Economies of scale – Now we can have a few people creating/managing images while maintaining a distributed build platform
- Scalable build process – Every Dev team has their own Jenkins without the overhead associated with managing it
- Jenkins servers can be upgraded, replaced, redeployed, refactored, screwed up, thrown out, crapped on and we can be back to a running state in a matter of minutes. WOOHOO Jenkins is now cattle.
- Standardized containers means less time spent troubleshooting
- Less chance of unrecognized security concerns across the landscape
- Accelerated time to market with even less risk
Lets be realistic, there are always benefits and limitations to anything and this design is not the exception.
Here are some difficulties SO FAR:
- Process challenges in adjusting to change
- Devs can’t run whatever version for a given language they want
- Devs could be prevented from taking advantage of new features in the latest versions of say Java IF the App Eng team can’t keep up
Worth Mentioning:
- Both Devs and App Eng don’t have direct access to Jenkins servers
- Because direct access is discourage, exceptional logging combined with exceptional analytics is an absolute must
Ok so if you made it thus far. I’m either a damn good writer, your seriously interested in what I have to say or you totally crazy about build pipelines. Somehow I don’t think its option 1. Cheers
@devoperandi