
Deploying many distributed clustering technologies in Kubernetes can require some finesse. Not so with Consul. It dead simple.
We deploy Consul with Terraform as a part of our Kubernetes cluster deployment strategy. You can read more about it here.
We currently deploy Consul as a 3 node cluster with 2 Kubernetes configuration files. Technically we could narrow it down to one but we tend to keep our service configs separate.
- consul-svc.yaml – to create a service for other applications to interact with
- consul.yaml – to create consul servers in a replication controller
When we bring up a new Kubernetes cluster, we push a bunch of files to Amazon S3. Along with those files are the two listed above. The Kubernetes Master pulls these files down from S3 and places them along with others in /etc/kubernetes/addons/ directory. We then execute everything in /etc/kubernetes/addons in a for loop using kubectl create -f.
Lets take a look at consul-svc.yaml
---
apiVersion: v1
kind: Service
metadata:
name: svc-consul
namespace: kube-system
labels:
name: consul-svc
spec:
ports:
# the port that this service should serve on
- name: http
port: 8500
- name: rpc
port: 8400
- name: serflan
port: 8301
- name: serfwan
port: 8302
- name: server
port: 8300
- name: consuldns
port: 8600
# label keys and values that must match in order to receive traffic for this service
selector:
app: consul
Nothing special about consul-svc.yaml. Just a generic service config file.
So what about consul.yaml
apiVersion: v1
kind: ReplicationController
metadata:
namespace: kube-system
name: consul
spec:
replicas: 3
selector:
app: consul
template:
metadata:
labels:
app: consul
spec:
containers:
- name: consul
command: [ "/bin/start", "-server", "-bootstrap-expect", "3", "-atlas", "account_user_name/consul", "-atlas-join", "-atlas-token", "%%ATLAS_TOKEN%%" ]
image: progrium/consul:latest
imagePullPolicy: Always
ports:
- containerPort: 8500
name: ui-port
- containerPort: 8400
name: alt-port
- containerPort: 53
name: udp-port
- containerPort: 443
name: https-port
- containerPort: 8080
name: http-port
- containerPort: 8301
name: serflan
- containerPort: 8302
name: serfwan
- containerPort: 8600
name: consuldns
- containerPort: 8300
name: server
Of all this code, there is one important line.
command: [ "/bin/start", "-server", "-bootstrap-expect", "3", "-atlas", "account_user_name/consul", "-atlas-join", "-atlas-token", "%%ATLAS_TOKEN%%" ]
-bootstrap-expect – sets the number of consul servers that need to join before bootstrapping
-atlas – enables atlas integration
-atlas-join – enables auto-join
-atlas-token – sets a token you can get from your Atlas account.
Note: make sure to replace ‘account_user_name’ with your atlas account user name.
Getting an atlas account for this purpose is free so don’t hesitate but make sure you realize, the token you generate should be highly highly secure.
So go sign up for an account. Once done click on your username in the upper right hand corner then click ‘Tokens’.
You’ll see something like this:
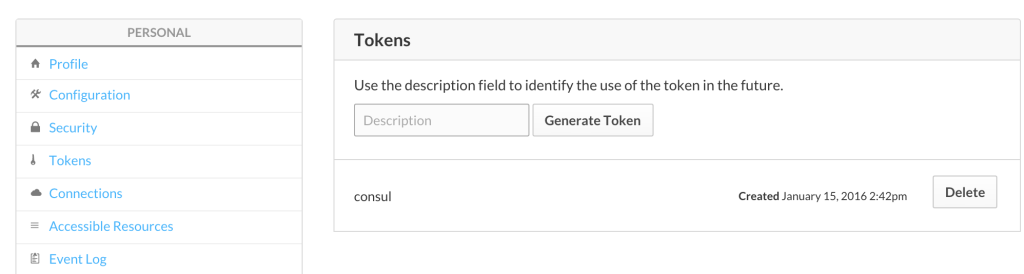
Generate a token with a description and use this token in %%ATLAS_TOKEN%% in the consul.yaml above.
In order to populate the Token at run time, we execute a small for loop to perform a sed replace before running ‘kubectl create -f’ on the yamls.
for f in ${dest}/*.yaml ; do
# Consul template
# Deprecated we no longer use CONSUL_SERVICE_IP
# sed -i "s,%%CONSUL_SERVICE_IP%%,${CONSUL_SERVICE_IP}," $f
sed -i "s,%%ATLAS_TOKEN%%,${ATLAS_TOKEN}," $f
done
The two variables listed above get derived from a resource “template_file” in Terraform.
Note: I’ve left out volume mounts from the config. Needless to say, we create volume mounts to a default location and back those up to S3.
Good Luck and let me know if you have questions.
@devoperandi
You “sed” the %%CONSUL_SERVICE_IP%% in your yaml template. But I cannot find it there. Is it deprecated.
My apologies. Yes you are correct. We have moved to using Atlas Token for clustering. I’ll adjust the blog post shortly.
Hi,
it looks to me using atlas requires internet connetions for all the deploying nodes. right?
I get the following err messages:
2016/04/08 21:54:50 [ERR] scada-client: failed to dial: dial tcp: lookup scada.hashicorp.com on 192.168.3.10:53: read udp 172.16.42.30:39927->192.168.3.10:53: i/o timeout
2016/04/08 21:54:51 [ERR] agent: failed to sync remote state: No cluster leader
2016/04/08 21:54:56 [ERR] agent: coordinate update error: No cluster leader
2016/04/08 21:55:12 [ERR] agent: coordinate update error: No cluster leader
2016/04/08 21:55:17 [ERR] agent: failed to sync remote state: No cluster leader
2016/04/08 21:55:28 [ERR] agent: coordinate update error: No cluster leader
Allen,
Yes, your pods will require outbound internet access. We run ours through a NAT box. It connects to Atlas which keeps a record of all the consul servers that have called in for a given token. This allows the consul servers to find one another and cluster up.
There are a couple of other methods to cluster Consul in containers but this is what we currently use.
Best Regards,
Michael,
I am curious – is this still the method you are using?
Thanks,
Tanner
No. I have a more recent blog post about deploying consul without atlas.
https://www.devoperandi.com/cluster-consul-using-kubernetes-api/
Hi,
I am trying to cluster Consul in k8s with no hardcoded ip address in the k8s yaml files. it looks not working when using the service ip as the join ip.
==> Starting Consul agent…
==> Starting Consul agent RPC…
==> Joining cluster…
==> read tcp 172.16.1.26:56398->192.168.3.7:8301: read: connection reset by peer
Can you help?
Allen,
We found the same thing which is why we use Atlas currently instead. Atlas prevents having to specify a join IP.
There are a couple of ways to achieve this,
1) specify the internal IP addresses for the containers so you know what to join up with.
2) specify a service for each consul server, thus ensuring each one has a separate ip to reference.
3) write an entrypoint script to write IPs off to a common location, and have the script select one for joining.
In the end, we found it cleaner to simply use atlas.
Hi,
Actually I am trying the way #2 you mentioned. I’ve specifed a service for each consul server and the service ip can be easily referenced with the k8s provided env. below is the comman line used to join the master node:
command: [ “/bin/consul”, “agent”, “-server”, “-advertise”, “$(CONSUL_SVC2_SERVICE_HOST)”, “-data-dir”, “/tmp/consul”, “-join”, “$(CONSUL_SVC1_SERVICE_HOST)”]
Well, as I mentioned, this is not working. I believe this is what you said “the same thing”.
This is going to be highly dependent on what container image you are using for the exact syntax. Assuming progrium/consul, try something like
command: [ "/bin/start", "-server", "-bootstrap-expect", "3", “-data-dir”, “/tmp/consul”, “-join”, “$(CONSUL_SVC1_SERVICE_HOST)” ]Some error information would help if you would like additional help.
We built an image from gliderlabs now that we use instead of progrium/consul:
+FROM gliderlabs/consul-agent:0.6
+ADD ./config /config/
+ENTRYPOINT []
(I’ve been reading up on Kube for a week or so, and am just getting started trying to deploy stuff using it, so grain of salt/caveat emptor/etc.)
If the atlas token is supposed to be secure, why not use it with a Kubernetes Secret? It should be straightforward to add it as a secret, reference it in the RC def and use it in the command expansion?
Keep in mind Kubernetes Secrets aren’t really ‘secret’. They are base64 encoded strings. Which can easily be decoded.
It however is still is a better method than we originally implemented. With the ability to constrain Kubernetes secrets per namespace, this makes even more sense however I’m not sure this was the case when we originally implemented.
Our intent long-term is to have a global Vault that will provide this data as we move toward a Multi-Region deployment model. We’ll talk more about this in the coming months.
How do you deal with reconnect_timeout min of 8 hours?
For my cluster of 5 consul nodes, over time K8S will reschedule pods elsewhere and the new pods will register themselves with Atlas, but Atlas doesn’t forget about the old nodes. Eventually I end up with 10 nodes, 5 of them unreachable, and Consul thinks it can’t form a quorum or elect a leader.
Trevor,
I agree, the 8 hour timeout can be painful. Especially when upgrading and rotating through your servers. We had to create a way to remove containers from the consul cluster as we migrate them to new servers.
But it sounds like you have some instability in your cluster if your containers are changing that often under normal circumstances. Are you loosing hosts often? We have seen issues with a Jenkins plugin (which we promptly removed) and the Ingress Controller creating zombies and eventually killing off hosts once they hit their file handle limit.
If sounds to me that while the 8 hour timeout can be and issue, you shouldn’t be loosing containers at anywhere near that pace. Are each of your consul containers dispersed across different hosts?
I’m on GKE so I don’t have fine-grained control over what happens when I upgrade K8S on each node. I’m not sure it’s sending a SIGTERM to each pod or just forcibly shutting down the VM. I also don’t know how I ended up with the 10 node situation: I did not run a rolling upgrade during this time; it happened over 12 days, and K8S on GKE apparently doesn’t preserve event logs (the kind that show up in `kubectl describe`).
GKE is generally pretty stable so I’d be surprised if you were loosing VMs that often as a result of the infrastructure (ie google problem). I’d be more inclined to take a look at the servers themselves. You need to find out if you are loosing VMs. If so look for defunct (zombie) processes with something like:
ps -ef | grep defunctIf you see a bunch of these, then you probably have pods that are spinning off zombies processes without ever being cleaned up. This will eventually fill your file descriptors and crash the server. Even more importantly, because Kubernetes distributes pods as best it can, I’ve found I’ll often loose VMs in fairly rapid succession as a result of this.
Personally this is the only situation I’ve run into in which we have lost numerous VMs in a short period of time on Kubernetes.
Look around here to see if you are loosing nodes:

Thanks for the debugging tips Michael, super helpful!
I think the greater point though is how to deal with failure in general. In any distributed system, there will be failures where a node doesn’t have a chance to gracefully de-register itself. Any system needs to be able to deal with that, whether via manual intervention/reconfiguration (boring) or automatically (awesome!), right? It appears Consul requires the manual flavor.
I agree. The 8 hour minimum limit is painful.
Oh and to be clear about how I lost nodes, it happened when upgrading kubectl. GKE takes a node down, upgrade kubectl, puts it back in, and apparently doesn’t SIGTERM the pods.
Hey Michael,
I was wondering how you manage to keep your data persistent?
In a 3 nodes cluster, if a Consul container dies a new one will be created and the data synced, but if for some reason all the containers were killed, then all the data would be lost.
Thanks!
Juice,
We are running a 5 node cluster split across multiple AZs. We have the Consul nodes on persistent local disk that backed up regularly for DR scenarios.
Michael
Hey Michael,
I’m not sure to understand how you manage to have each node on a local persistent disk. Do you mean that you backup the disk of every k8s minion on which there could be a consul node running?
Or are you talking about using disks as volumes that you would mount as a volume?
Thanks!
Juice,
I was 100% wrong. my bad. We have changed significantly since I last looked at our Consul setup and I completely failed to relook at it before commenting. We are using consulate from https://github.com/gmr/consulate to backup Consul through the HTTP API. It works exceptionally well.
consulate --api-host ${CONSUL_SERVICE_IP} \
--api-port ${CONSUL_SERVICE_PORT} \
--datacenter ${ENVIRONMENT} \
--token ${CONSUL_MASTER_TOKEN} \
kv restore -b -f ${BACKUP_FILE}
Michael,
Thanks so much for the update! I had in mind to do a similar thing, but I did not know about consulate, it looks great!
It’s becoming somewhat complicated to just have every consul have persistent data. So in the end, I’ll run the consul servers in containers with no persistent storage but back them up often. That way, if all the containers happen to die at the same time (which would probably mean a major outage is going on on all k8s minions), I’ll be able to just restore the data.
Would you recommend such a thing?
Thanks so much for your input 🙂
While its certainly easier to run it that way, I still have to say write off to disk. If nothing other than to know your latest transactions in your k/v store are written somewhere. Even if you are backing the data up every 5 minutes, which would be quite often, you have to evaluate how much data (ie the delta from the last backup to the time your consul cluster crashed) you could be loosing in a disaster scenario. If you only read from that data store and it almost never gets written to, then that might be a scenario in which you could get away with no disk.
(Answering to your last comment).
I can’t disagree with you, that makes a lot of sense. Yet I’m not certain to understand how you manage to have all consule nodes write to disk.
Did you find a way to mount a volume (e.g. an EBS disk) onto each containers? It’s really the part where all nodes write to disk that bugs me.
You can configure a cloud provider in K8s which can allow you to manage EBS volumes.
https://github.com/kubernetes/kubernetes/tree/master/examples/experimental/persistent-volume-provisioning
Its experimental.
The current stable method is to create the EBS volumes ahead of time and then mount them.
http://kubernetes.io/docs/user-guide/volumes/
http://kubernetes.io/docs/user-guide/volumes/#aws-ebs-example-configuration