
WARNING!!! Beta – Not yet for production.
You might be thinking right now, third party resources? Seriously? With all the amazing stuff going on right now around Kubernetes and you want to talk about that thing at the bottom of the list. Well keep reading, hopefully by the end of this, you too will see the light.
Remember last week when I talked about future projects in my Python Client For Kubernetes blog? Well here it is. One key piece of our infrastructure is quickly becoming StackStorm.
What’s StackStorm you might ask? StackStorm is an open source event driven automation system which hailed originally from OpenStack’s Mistral workflow project. In fact, some of its libraries are from mistral but its no longer directly tied to OpenStack. Its a standalone setup that rocks. As of the time of this writing, StackStorm isn’t really container friendly but they are working to remediate this and I expect a beta to be out in the near future. Come on guys, hook a brother up.
For more information on StackStorm – go here.
I’ll be the first to admit, there documentation took me a little while to grok. Too many big words and not enough pics to describe what’s going on. But once I got it, nothing short of meeting Einstein could have stopped my brain from looping through all the possibilities.
Lets say, we want to manage an RDS database from Kubernetes. We should be able to create, destroy, configure it in conjunction with the application we are running and even more importantly, it must be a fully automated process.
So what’s it take to accomplish something like this? Well in our minds we needed a way to present objects externally i.e. third party resources and we need some type of automation that can watch those events and act on them ala StackStorm.
Here is a diagram of our intentions: We have couple loose ends to complete but soon we’ll be capable of performing this workflow for any custom resource. Database just happens to be the first requirement we had that fit the bill.
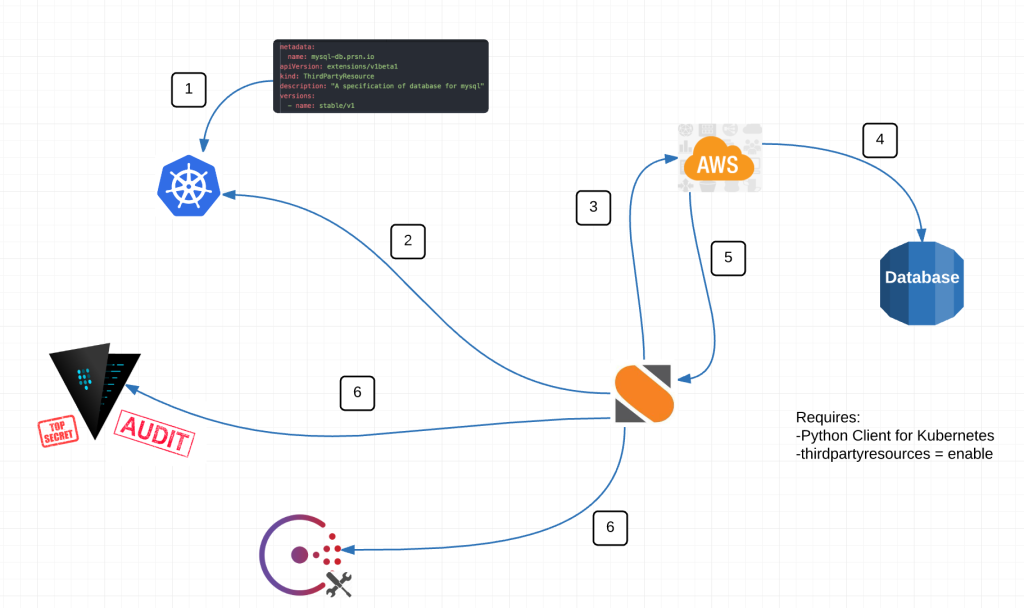
In the diagram above we are perform 6 basic actions.
– Input thirdpartyresource to Kubernetes
– StackStorm watches for resources created, deleted OR modifed
– If trigger – makes call to AWS API to execute an event
– Receives back information
– On creation or deletion, adds or remove necessary information from Vault and Consul
Alright from the top, what is a third party resource exactly? Well its our very own custom resource. Kind of like a pod, endpoint or replication controller are API resources but now we get our own.
Third Party Resources immediately stood out to us because we now have the opportunity to take advantage of all the built-in things Kubernetes provides like metadata, labels, annotations, versioning, api watches etc etc while having the flexibility to define what we want in a resource. What’s more, third party resources can be grouped or nested.
Here is a an example of a third party resource:
metadata:
name: mysql-db.prsn.io
labels:
resource: database
object: mysql
apiVersion: extensions/v1beta1
kind: ThirdPartyResource
description: "A specification of database for mysql"
versions:
- name: stable/v1
This looks relatively normal with one major exception. The metadata.name = mysql-db.prsn.io. I’ve no idea why but you must have a fully qualified domain in the name in order for everything to work properly. The other oddity is the “-“. It must be there and you must have one. Something to do with <CamelCaseKind>.
Doing this creates
/apis/prsn.io/stable/v1/namespaces/<namespace>/mysqls/...
By creating the resource above, we have essentially created our very own api endpoint by which to get all resources of this type. This is awesome because now we can create mysql resources and watch them under one api endpoint for consumption by StackStorm.
Now imagine applying a workflow like this to ANYTHING you can wrap your head around. Cool huh?
Remember this is beta and creating resources under the thirdpartyresource (in this case mysqls) requires a little curl at this time.
{
"metadata": {
"name": "my-new-mysql-db"
},
"apiVersion": "prsn.io/stable/v1",
"kind": "MysqlDb",
"engine_version": "5.6.23",
"instance_size": "huge"
}
There are three important pieces here. 1) its json. 2) apiVersion has the FQDN + versions.name for the thirdpartyresource. 3) kind = MysqlDb <CamelCaseKind>
Now we can curl the Kubernetes api and post this resource.
curl -d "{"metadata":{"name":"my-new-mysql-database"},"apiVersion":"prsn.io/stable/v1","kind":"MysqlDb","engine_version":"5.6.23","instance_size":"huge"}" https://kube_api_url
Now if you hit you kubernetes api endpoint you should see something like this:
{
"paths": [
"/api",
"/api/v1",
"/apis",
"/apis/extensions",
"/apis/extensions/v1beta1",
"/apis/prsn.io",
"/apis/prsn.io/stable/v1",
"/healthz",
"/healthz/ping",
"/logs/",
"/metrics",
"/resetMetrics",
"/swagger-ui/",
"/swaggerapi/",
"/ui/",
"/version"
]
}
Our very own Kubernetes endpoint now in /apis/prsn.io/stable/v1.
And here is a resource under the mysql thirdpartyresource located at:
/apis/prsn.io/stable/v1/mysqldbs
{
"kind": "MysqlDb",
"items": [
{
"apiVersion": "prsn.io/stable/v1",
"kind": "MysqlDb",
"metadata": {
"name": "my-new-mysql-db",
"namespace": "default",
"selfLink": "/apis/prsn.io/stable/v1/namespaces/default/mysqldbs/my-new-mysql-db"
...
}
}
]
}
If your mind isn’t blown by this point, move along, I’ve got nothin for ya.
Ok on to StackStorm.
Within StackStorm we have a Sensor that watches the Kubernetes api for a given third party resource. In this example, its looking for MysqlDb resources. From there it compares the list of MysqlDb resources against a list of mysql databases (rds in this case) that exist and determines what/if any actions it needs to perform. The great thing about this is StackStorm already has quite a number of what they call packs. Namely an AWS pack. So we didn’t have to do any of the heavy lifting on that end. All we had to do was hook in our python client for Kubernetes, write a little python to compare the two sets of data and trigger actions based off the result.
It also has a local datastore so if you need to store key/value pairs for any length of time, that’s quite easy as well.
Take a look at the bottom of this page for operations against the StackStorm datastore.
We’ll post our python code as soon as it makes sense. And we’ll definitely create a pull request back to the StackStorm project.
Right now we are building the workflow to evaluate what actions to take. We’ll update this page as soon as its complete.
If you have questions or ideas on how else to use StackStorm and ThirdPartyResources, I would love to hear about them. We can all learn from each other.
@devoperandi
Other beta stuff:
deployments – https://github.com/kubernetes/kubernetes/blob/master/docs/proposals/deployment.md
horizontalpodautoscaler – https://github.com/kubernetes/kubernetes/blob/release-1.1/docs/design/horizontal-pod-autoscaler.md
ingress – http://kubernetes.io/v1.1/docs/user-guide/ingress.html
Which to be fair I have talked about this in the blog about Load Balancing
jobs – https://github.com/kubernetes/kubernetes/blob/release-1.1/docs/user-guide/jobs.md
No part of this blog is sponsored or paid for by anyone other than the author.
Thanks, this is awesome. Any pointers to getting StackStorm running on K8s as well?
We aren’t currently running StackStorm inside Kubernetes. We are looking forward to it though as there are quite a few excellent opportunities for us once we can. The StackStorm project is placing focus on containerizing it soon but its not done yet.