
While some may disagree, personally I think Kubernetes is becoming the defacto standard for anyone wishing to orchestrate containers in wide scale deployments. It has good api support, is under active development, is backed by various large companies, is completely open-source, is quite scalable for most workloads and has a pretty good feature set for initial release.
Now having used it for sometime now I’ll be the first to claim is has some shortcomings. Things like external load balancing (Ingresses), autoscaling and persistent storage for things like databases would be pretty good ones to point out. But these also happen to be under active development and I expect will have viable solutions in the near future.
Load Balancing – Ingresses and Ingress Controllers
Autoscaling – built into Kubernetes soon
Persistent Storage – Kubernetes-Ceph/Flocker
So what about MultiAZ deployments?
We deploy/manage Kubernetes using Terraform (Hashicorp). Even though Terraform isn’t technically production ready yet, I expect it to fill a great role in our future deployments so we were willing to accept its relative immaturity for its ever expanding feature set.
You can read more about Terraform here. We are using several of their products including Vault and Consul.
Terraform:
- Creates a VPC, subnets, routes, security groups, ACLs, Elastic IPs and Nat machine
- Creates IAM users
- Creates a public and private hosted zone in route53 and adds dns entries
- Pushes data up to an AWS S3 bucket with dynamically generated files from Terraform
- Deploys autoscaling groups, launch configurations for master and minions
- Sets up an ELB for the Kubernetes Master
- Deploys the servers with user-data
Create the VPC
resource "aws_vpc" "example" {
cidr_block = "${var.vpc_cidr}"
instance_tenancy = "dedicated"
enable_dns_support = true
enable_dns_hostnames = true
tags {
Name = "example-${var.environment}"
}
}
resource "aws_internet_gateway" "default" {
vpc_id = "${aws_vpc.example.id}"
}
Create Routes
resource "aws_route53_record" "kubernetes-master" {
# domain.io zone id
zone_id = "${var.zone_id}"
# Have to limit wildcard to one *
name = "master.${var.environment}.domain.io"
type = "A"
alias {
name = "${aws_elb.kube-master.dns_name}"
zone_id = "${aws_elb.kube-master.zone_id}"
evaluate_target_health = true
}
}
resource "aws_route53_zone" "vpc_zone" {
name = "${var.environment}.kube"
vpc_id = "${aws_vpc.example.id}"
}
resource "aws_route53_record" "kubernetes-master-vpc" {
zone_id = "${aws_route53_zone.vpc_zone.zone_id}"
name = "master.${var.environment}.kube"
type = "A"
alias {
name = "${aws_elb.kube-master.dns_name}"
zone_id = "${aws_elb.kube-master.zone_id}"
evaluate_target_health = true
}
}
Create Subnets – Example of public subnet
/*
Public Subnet
*/
resource "aws_subnet" "us-east-1c-public" {
vpc_id = "${aws_vpc.example.id}"
cidr_block = "${var.public_subnet_cidr_c}"
availability_zone = "${var.availability_zone_c}"
tags {
Name = "public-subnet-${var.environment}-${var.availability_zone_c}"
Environment = "${var.environment}"
}
}
resource "aws_subnet" "us-east-1a-public" {
vpc_id = "${aws_vpc.example.id}"
cidr_block = "${var.public_subnet_cidr_a}"
availability_zone = "${var.availability_zone_a}"
tags {
Name = "public-subnet-${var.environment}-${var.availability_zone_a}"
Environment = "${var.environment}"
}
}
resource "aws_subnet" "us-east-1b-public" {
vpc_id = "${aws_vpc.example.id}"
cidr_block = "${var.public_subnet_cidr_b}"
availability_zone = "${var.availability_zone_b}"
tags {
Name = "public-subnet-${var.environment}-${var.availability_zone_b}"
Environment = "${var.environment}"
}
}
resource "aws_route_table" "us-east-1c-public" {
vpc_id = "${aws_vpc.example.id}"
route {
cidr_block = "0.0.0.0/0"
gateway_id = "${aws_internet_gateway.default.id}"
}
tags {
Name = "public-subnet-${var.environment}-${var.availability_zone_c}"
Environment = "${var.environment}"
}
}
resource "aws_route_table" "us-east-1a-public" {
vpc_id = "${aws_vpc.example.id}"
route {
cidr_block = "0.0.0.0/0"
gateway_id = "${aws_internet_gateway.default.id}"
}
tags {
Name = "public-subnet-${var.environment}-${var.availability_zone_a}"
Environment = "${var.environment}"
}
}
resource "aws_route_table" "us-east-1b-public" {
vpc_id = "${aws_vpc.example.id}"
route {
cidr_block = "0.0.0.0/0"
gateway_id = "${aws_internet_gateway.default.id}"
}
tags {
Name = "public-subnet-${var.environment}-${var.availability_zone_b}"
Environment = "${var.environment}"
}
}
resource "aws_route_table_association" "us-east-1c-public" {
subnet_id = "${aws_subnet.us-east-1c-public.id}"
route_table_id = "${aws_route_table.us-east-1c-public.id}"
}
resource "aws_route_table_association" "us-east-1a-public" {
subnet_id = "${aws_subnet.us-east-1a-public.id}"
route_table_id = "${aws_route_table.us-east-1a-public.id}"
}
resource "aws_route_table_association" "us-east-1b-public" {
subnet_id = "${aws_subnet.us-east-1b-public.id}"
route_table_id = "${aws_route_table.us-east-1b-public.id}"
}
}
Create Security Groups– Notice how the ingress is only to the vpc cidr block
/*
Kubernetes SG
*/
resource "aws_security_group" "kubernetes_sg" {
name = "kubernetes_sg"
description = "Allow traffic to pass over any port internal to the VPC"
ingress {
from_port = 0
to_port = 65535
protocol = "tcp"
cidr_blocks = ["${var.vpc_cidr}"]
}
egress {
from_port = 0
to_port = 65535
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
ingress {
from_port = 0
to_port = 65535
protocol = "udp"
cidr_blocks = ["${var.vpc_cidr}"]
}
egress {
from_port = 0
to_port = 65535
protocol = "udp"
cidr_blocks = ["0.0.0.0/0"]
}
egress {
from_port = 0
to_port = 65535
protocol = "udp"
cidr_blocks = ["0.0.0.0/0"]
}
vpc_id = "${aws_vpc.example.id}"
tags {
Name = "kubernetes-${var.environment}"
}
}
Create the S3 bucket and add data
resource "aws_s3_bucket" "s3bucket" {
bucket = "kubernetes-example-${var.environment}"
acl = "private"
force_destroy = true
tags {
Name = "kubernetes-example-${var.environment}"
Environment = "${var.environment}"
}
}
You’ll notice below is an example of a file pushed to S3. We add depends_on aws_s3_bucket because Terraform will attempt to add files to the S3 bucket before it is created without it. (To be fixed soon according to Hashicorp)
resource "aws_s3_bucket_object" "setupetcdsh" {
bucket = "kubernetes-example-${var.environment}"
key = "scripts/setup_etcd.sh"
source = "scripts/setup_etcd.sh"
depends_on = ["aws_s3_bucket.s3bucket"]
}
We distribute the cluster across 3 AZs, with 2 subnets (1 public, 1 private) per AZ. We allow internet access to the cluster through Load Balancer minions and the Kubernetes Master only. This reduces our exposure while maintaining scalability of load throughout.
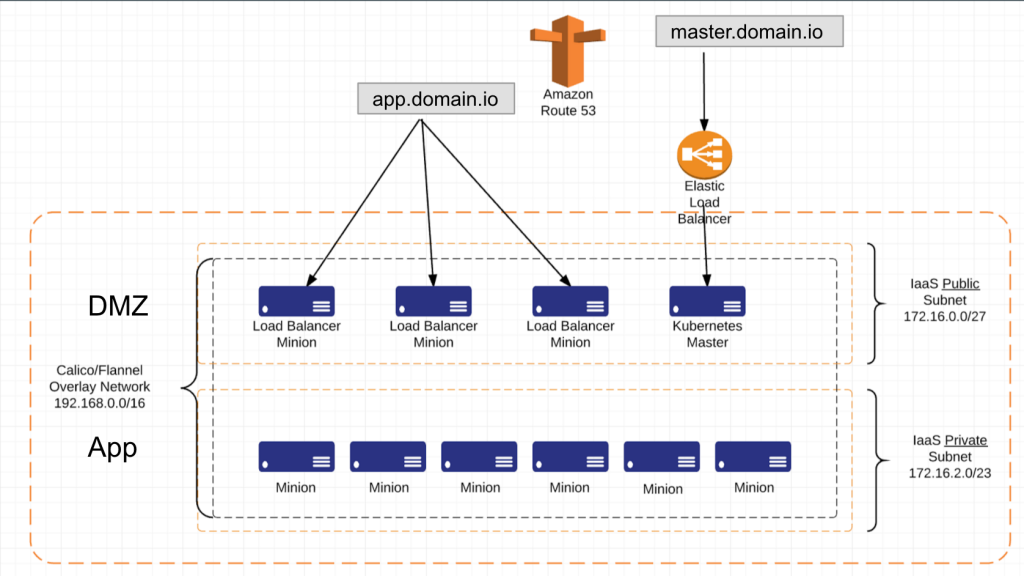
Load Balancer minions are just Kubernetes minions with a label of role=loadbalancer that we have chosen to deploy into the DMZ so they have exposure to the internet. They are also in an AutoScaling Group. We have added enough logic into the creation of these minions for them to assign themselves a pre-designated, Terraform created Elastic IP. We do this because we have A records pointing to these Elastic IPs in a public DNS zone and we don’t want to worry about DNS propagation.
In order to get Kubernetes into multiple availability zones we had to figure out what to do with etcd. Kubernetes k/v store. Many people are attempting to distribute etcd across AZs with everything else but we found ourselves questioning the benefit of that. If you have insights into it that we don’t, feel free to comment below. We currently deploy etcd in typical fashion with the Master, the API server, the controller and the scheduler. Thus there wasn’t much reason to distribute etcd. If the API or the Master goes down, having etcd around is of little benefit. So we chose to backup etcd on a regular basis and push that out to AWS S3. The etcd files are small so we can expect to back it up often without incurring any severe penalties. We then deploy our Master into an autoscaling group with scaling size of min=1 and max=1. When the Master comes up, it automatically attempts to pull in the etcd files from S3 (if available) and starts up its services. This combined with some deep health checks allows the autoscaling group to rebuild the master quickly.
We do the same with all our minions. They are created with autoscaling groups and deployed across multiple AZs.
We create a launch configuration that uses an AWS AMI, instance type (size), associates a public IP (for API calls and proxy requests), assigns some security groups, and adds some EBS volumes. Notice the launch configuration calls a user-data file. We utilize user-data heavily to provision the servers.
AWS launch configuration for the Master:
resource "aws_launch_configuration" "kubernetes-master" {
image_id = "${var.centos_ami}"
instance_type = "${var.instance_type}"
associate_public_ip_address = true
key_name = "${var.aws_key_name}"
security_groups = ["${aws_security_group.kubernetes_sg.id}","${aws_security_group.nat.id}"]
user_data = "${template_file.userdatamaster.rendered}"
ebs_block_device = {
device_name = "/dev/xvdf"
volume_type = "gp2"
volume_size = 20
delete_on_termination = true
}
ephemeral_block_device = {
device_name = "/dev/xvdc"
virtual_name = "ephemeral0"
}
ephemeral_block_device = {
device_name = "/dev/xvde"
virtual_name = "ephemeral1"
}
connection {
user = "centos"
agent = true
}
}
Then we deploy an autoscaling group that will describe the AZs to deploy into, min/max number of servers, health check, the launch configuration above and adds it to an ELB. We don’t actually use ELBs much in our deployment strategy but for the Master it made sense.
AutoScaling Group configuration:
resource "aws_autoscaling_group" "kubernetes-master" {
vpc_zone_identifier = ["${aws_subnet.us-east-1c-public.id}","${aws_subnet.us-east-1b-public.id}","${aws_subnet.us-east-1a-public.id}"]
name = "kubernetes-master-${var.environment}"
max_size = 1
min_size = 1
health_check_grace_period = 100
health_check_type = "EC2"
desired_capacity = 1
force_delete = false
launch_configuration = "${aws_launch_configuration.kubernetes-master.name}"
load_balancers = ["${aws_elb.kube-master.id}"]
tag {
key = "Name"
value = "master.${var.environment}.kube"
propagate_at_launch = true
}
tag {
key = "Environment"
value = "${var.environment}"
propagate_at_launch = true
}
depends_on = ["aws_s3_bucket.s3bucket","aws_launch_configuration.kubernetes-master"]
}
I mentioned earlier we use a user-data file to do quite a bit when provisioning a new Kubernetes minion or master. There are 5 primary things we use this file for:
- Polling the AWS API for an initial set of information
- Pulling dynamically configured scripts and files from S3 to create Kubernetes
- Exporting a list of environment variables for Kubernetes to use
- Creating an internal DNS record in Route53.
We poll the AWS API for the following:
Notice how we poll for the Master IP address which is then used for a minion to join the cluster.
MASTER_IP=`aws ec2 describe-instances --region=us-east-1 --filters "Name=tag-value,Values=master.${ENVIRONMENT}.kube" "Name=instance-state-code,Values=16" | jq '.Reservations[].Instances[].PrivateIpAddress'`
PUBLIC_IP=`curl http://169.254.169.254/latest/meta-data/public-ipv4`
PRIVATE_IP=`curl http://169.254.169.254/latest/meta-data/local-ipv4`
INSTANCE_ID=`curl http://169.254.169.254/latest/meta-data/instance-id`
AVAIL_ZONE=`curl http://169.254.169.254/latest/meta-data/placement/availability-zone`
List of environment variables to export:
MASTER_IP=$MASTER_IP
PRIVATE_IP=$PRIVATE_IP
#required for minions to join the cluster
API_ENDPOINT=https://$MASTER_IP
ENVIRONMENT=${ENVIRONMENT}
#etcd env config
LISTEN_PEER_URLS=http://localhost:2380
LISTEN_CLIENT_URLS=http://0.0.0.0:2379
ADVERTISE_CLIENT_URLS=http://$PRIVATE_IP:2379
AVAIL_ZONE=$AVAIL_ZONE
#version of Kubernetes to install pulled from Terraform variable
KUBERNETES_VERSION=${KUBERNETES_VERSION}
KUBERNETES_RELEASE=${KUBERNETES_RELEASE}
INSTANCE_ID=$INSTANCE_ID
#zoneid for route53 record retrieved from Terraform
ZONE_ID=${ZONE_ID}
When an AWS server starts up it runs its user-data file with the above preconfigured information.
We deploy Kubernetes using a base CentOS AMI that has been stripped down with docker and aws cli installed.
The server then pulls down the Kubernetes files specific to its cluster and role.
aws s3 cp --recursive s3://kubernetes-example-${ENVIRONMENT} /tmp/
It then runs a series of scripts much like what k8s.io runs. These scripts set the server up based on the config variables listed above.
Currently we label our Kubernetes minions to guarantee containers are distributed across multiple AZs but the Kubernetes project has some work currently in process that will allow minions to be AZ aware.
UPDATE: The ubernetes team has an active working group our their vision of Multi-AZ. You can read up on that here and see their meeting notes here. Once complete I expect we’ll move that direction as well.
Hi! Awesome write-up.. Do you have a git hub with some examples of minion/master provisioning scripts you are using? like the etcd script you mention, or the master install script?
I’m afraid it wouldn’t be terribly helpful. All we are doing is calling to AWS S3 for Kubernetes scripts located here and supplying the server with a list of environment variables for Kubernetes to configure itself with. Everything else is specific to our environment. This was intentional so we could easily upgrade our clusters. Feel free to reach out if you have more questions.