The day has finally come. Today we are announcing our open source project Environment Operator (EO).
Environment Operator is used throughout our project and has rapidly gained a name for itself as being well written and well thought out. Props go out to Simas Cepaitis, Cristian Radu and Ben Somogyi who have all contributed.
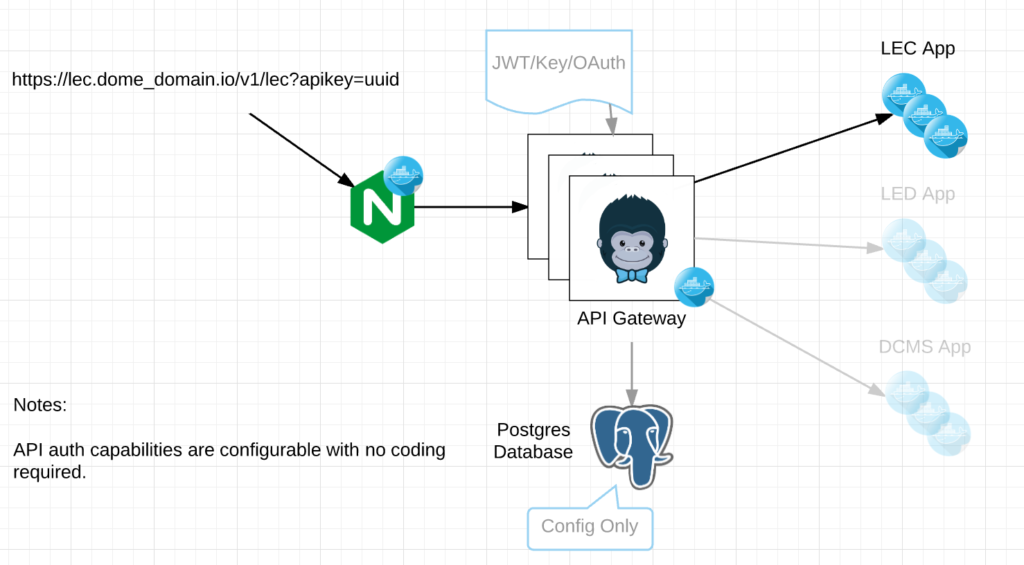
At its core, EO enables a seamless application deployment capability for a given environment/namespace within Kubernetes.
Benefits/Features:
- multi-cluster deployments
- audit trail
- status
- consistent definition of customer environments
- separate build from deploy
- minimizes risk and scope of impact
- simple abstraction from Kubernetes
- BYO CI/CD
- empowers our customers (dev teams)
- API interface
- multiple forms of authentication
- deploy through yaml config and API
- written in Go
- Docker Registries
Multi-Cluster Deployments – With EO running in each namespace and exposed via an API, CI/CD pipelines can simply call the API endpoint regardless of Kubernetes cluster and deploy new services.
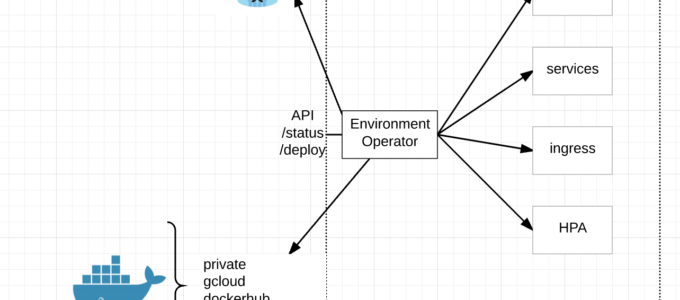
API Interface – EO has its own API endpoint for deployments, status, logs and the like. This combined with a yaml config for its environment is a very powerful combination.
Audit Trail – EO provides an audit trail of all changes to the environment through its logging to stdout.
Status – EO provides a /status endpoint by which to understand the status of an environment or individual services within the environment with /status/${service}
Separate Build from Deploy – What we found was, while our CI/CD pipeline is quite robust it lacked real-time feedback and audit capabilities needed by our dev teams. Separating our build from deploy allowed us to add in these additional features, simplify its use and enabled our dev teams to bring their own familiar pipelines to our project.
Minimize Risk and Scope of impact – Because EO runs inside the Kubernetes cluster we could limit its capabilities through Kubernetes service accounts to only its namespace. This limits risk and impact to other dev teams running in the same cluster as well as requiring a dev to call and entirely wrong API endpoint in order to effect another environment. Further more, authentication is setup for each EO, so separation of concerns between environments can easily be made.
Simple Abstraction – Because EO is so simple to use, it has enabled our teams to get up and running much faster in Kubernetes. Very little prior knowledge is required, they can use their same pipelines by using a common DSL in our Jenkins plugin and get all the real-time information all from one place per environment.
BYO CI/CD – I think this is pretty self-explanatory but we have many dev teams at Pearson that already have their own CI/CD pipelines. They can continue using their pipeline or choose to use ours.
Empower our Dev teams – Ultimately EO is about empowering Dev teams to manage their own environments without requiring tons of prior knowledge to get started. Simply deploy EO and go.
Authentication – EO currently supports two different kinds of authentication. Token based which gets pulled from a Kubernetes secret or OAuth. We currently tie directly into Keycloak for auth.
Plugin (DSL) for Jenkins – Because most of our Dev teams run Jenkins, we wrote a plugin to hook directly into it. Other plugins could very easily be written.
Docker Registries – EO can connect to private, public, gcloud and docker hub registries.
As you can see, Environment Operator has a fair amount of capabilities built-in but we aren’t stopping there.
Near term objectives:
- Stateful sets
- Kubernetes Jobs
- Prometheus
Github:
https://github.com/pearsontechnology/environment-operator
https://github.com/pearsontechnology/environment-operator-jenkins-plugin
Let us know what you think!
@devoperandi