Introduction
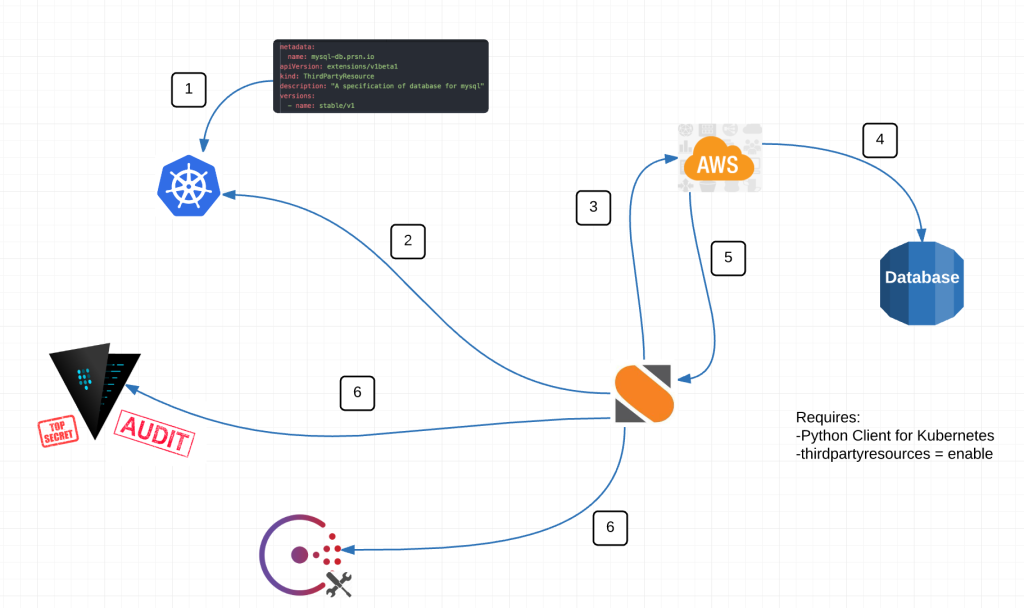
Stackstorm (st2) is a platform which you can use as an automation framework. St2 has many features to support automating software development on-prem or cloud.
St2 packs are the units of content deployment and you can use different actions on pack(s) to create workflows.
In this blogpost, I’m going to demonstrate how to use st2 aws boto3 pack to manage services on aws.
Setup St2 environment
First of all you need to have a development environment with st2 installed. It is very easy to setup a vagrant box with st2. You can use the link below to setup the vagrant environment with st2 instantly.
Also follow the Quick Start guide of st2 to get some hands on. You need to become aware of yourself about the concepts of pack, actions, etc.
St2 AWS pack
Once you setup the environment, it is super simple to install a pack. There are hundreds of packs available for you to download and you also can contribute to the pack development. Use the link stated below to search a pack based on your needs. For example, may be you want ansible pack to deal with ansible via st2.
However, I want to install st2 aws pack in this occasion. You can simply search and copy the command to install the pack on stackstorm-exchange.
st2 pack install aws
This is one version of the aws pack which has lots of actions. The aws boto3 pack, by contrast, is more powerful and simple due to very valid reasons. The main reasons are simplicity and minimum or zero maintenance of the pack. Let’s assume that, boto3 action adds a new parameter in future, but aws.boto3action needs zero changes, i’d rather say that, this action is immune to the changes in boto3 action(s).
You can install the aws boto3 pack using the command below;
st2 pack install aws=boto3
In this pack, you just need only two actions to do anything on AWS that is why I said, it is very simple. Those two actions are;
- aws.assume_role
- aws.boto3action
The aws.assume_role action
This action is used to get the AWS credentials using AWS assume role. For example, see below code snippet.
assume_role: action: aws.assume_role input: role_arn: <% $.assume_role %> publish: credentials: <% task(assume_role).result.result %>
In the preceding example, the aws.assume_role action has one input parameter which is AWS IAM role with proper permission. So basically, it needs to have required permission to perform various activities on AWS. For example, you may want to have ec2:* permission to manage EC2 related activities. It needs to have autoscaling:* permission to carry out autoscaling related activities so on and so forth.
Sample policy document for assume_role would be something like below;
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"ec2:*",
"iam:*",
"autoscaling:*",
"ssm:SendCommand",
"ssm:DescribeInstanceInformation",
"ssm:GetCommandInvocation"
],
"Effect": "Allow",
"Resource": "*"
}
]
}
When you pass an IAM role as assume role it returns AWS credentials and that credentials is saved in a variable to use at a later time. See the credentials variable under publish tag in the preceding yaml code snippet.
The aws.boto3action action
Let’s assume we need to get the information regarding a Launch Configuration. As per boto3, the relevant action to get Launch Configuration information is, describe_auto_scaling_groups. See the link mentioned below;
The describe_auto_scaling_groups action comes under AutoScaling service. Once you know these information you can interact this boto3 action within st2 as stated below;
action: aws.boto3action input: region: <% $.region %> service: autoscaling action_name: describe_launch_configurations params: <% dict(LaunchConfigurationNames => list($.lc_name)) %> credentials: <% $.credentials %>
Let’s go through each input in detail.
region: The AWS region that you want to perform the action.
service: The AWS service category. For example, ec2, autoscaling, efs,
iam, kinesis, etc. Check all the available service in boto3 using the link below;
action_name: Name of the boto3 action. In the above example, it is, describe_launch_configurations.
params: Input parameters for the action, describe_launch_configurations in this case. It has to be passed as a dict. You can refer the boto3 action to get a detailed explanation about the parameters and their data types. Please note that , lc_name is a input parameter which specifies the name of Launch Configuration.
You should feel free to poke around and see how this st2 aws boto3 pack works.
The aws.boto3action is used to execute relevant boto3 actions vis st2.
Summary
Six months ago, I started using st2. In fact Mike is the one who is responsible. He tasked me with database automation work using st2. So I definitely should thank him for that because I learned quite a bit.
The aws boto3 pack is designed with an eye towards the future, that is why it is protected from the changes in boto3 world which I believe is the most important factor when it comes software design. When you start using this pack, it will quickly become apparent how easy it is to use.
Discussion on the future of the AWS pack
Cheers!