
In the beginning, there was logging ……… AND there were single homed, single server applications, engineers to rummage through server logs, CDs for installing OSs and backup tape drives. Fortunately most everything else has gone the way of the dodo. Unfortunately, logging in large part has not.
When we started our PaaS project, we recognized logging was going to be of interest in a globally distributed, containerized, volatile, ever changing environment. CISO, QA and various business units all have data requirements that can be gathered from logs. All having different use cases and all wanting log data they can’t seem to aggregate together due to the distributed nature of our organization. Now some might think, we’ve done that. We use Splunk or ELK and pump all the logs into it and KA-CHOW!!! were done. Buutttt its not quite that simple. We have a crap ton of applications, tens of thousands of servers, tons of appliances, gear and stuff all over the globe. We have one application that literally uses 1 entire ELK stack by itself because the amount of data its pumping out is so ridiculous.
So with project Bitesize coming along nicely, we decided to take our first baby step into this realm. This is a work in progress but here is the gist. Dynamically configured topics through fluentd containers running in Kubernetes on each server host. A scalable Kafka cluster that holds data for a limited amount of time. Saves data off to permanent storage for long-term/bulk analytics. A Rest API or http interface. A management tool for security of the endpoint.
Where we’re at today is dynamically pushing data into Kafka via Fluentd based on Kubernetes namespace. So what does that mean exactly? EACH of our application stacks (by namespace) can get their own logs for their own applications without seeing everything else.
I’d like to give mad props to Yiwei Chen for making this happen. Great work mate. His image can be found on Docker hub at ywchenbu/fluentd:0.8.
This image contains just a few key fluentd plugins.
fluentd-kubernetes-metadata-filter
fluentd-record-transformer – built into fluentd. No required install.
We are still experimenting with this so expect it to change but it works quite nicely and could be modified for use cases other than topics by namespace.
You should have the following directory in place on each server in your cluster.
Directory – /var/log/pos # So fluentd can keep track of its log position
Here is td-agent.yaml.
apiVersion: v1
kind: Pod
metadata:
name: td-agent
namespace: kube-system
spec:
volumes:
- name: log
hostPath:
path: /var/log/containers
- name: dlog
hostPath:
path: /var/lib/docker/containers
- name: mntlog
hostPath:
path: /mnt/docker/containers
- name: config
hostPath:
path: /etc/td-agent
- name: varrun
hostPath:
path: /var/run/docker.sock
- name: pos
hostPath:
path: /var/log/pos
containers:
- name: td-agent
image: ywchenbu/fluentd:0.8
imagePullPolicy: Always
securityContext:
privileged: true
volumeMounts:
- mountPath: /var/log/containers
name: log
readOnly: true
- mountPath: /var/lib/docker/containers
name: dlog
readOnly: true
- mountPath: /mnt/docker/containers
name: mntlog
readOnly: true
- mountPath: /etc/td-agent
name: config
readOnly: true
- mountPath: /var/run/docker.sock
name: varrun
readOnly: true
- mountPath: /var/log/pos
name: pos
You will probably notice something thing about this config that we don’t like. The fact that its running in privileged mode. We intend to change this in near future but currently fluentd cant read the log files without it. Not a difficult change, just haven’t made it yet.
This yaml gets placed in
/etc/kubernetes/manifests/td-agent.yaml
Kubernetes should automatically pick this up and deploy td-agent.
And here is where the magic happens. Below is td-agent.conf. Which according to our yaml should be located at
/etc/td-agent/td-agent.conf
<source>
type tail
path /var/log/containers/*.log
pos_file /var/log/pos/es-containers.log.pos
time_format %Y-%m-%dT%H:%M:%S.%NZ
tag kubernetes.*
format json
read_from_head true
</source>
<filter kubernetes.**>
type kubernetes_metadata
</filter>
<filter **>
@type record_transformer
enable_ruby
<record>
topic ${kubernetes["namespace_name"]}
</record>
</filter>
<match **>
@type kafka
zookeeper SOME_IP1:2181,SOME_IP2:2181 # Set brokers via Zookeeper
default_topic default
output_data_type json
output_include_tag false
output_include_time false
max_send_retries 3
required_acks 0
ack_timeout_ms 1500
</match>
What’s happening here?
- Fluentd is looking for all log files in /var/log/containers/*.log
- Our kubernetes-metadata-filter is adding info to the log file with pod_id, pod_name, namespace, container_name and labels.
- We are transforming the data to use the namespace as the kafka topic
- And finally pushing the log entry to Kafka.
Here is an example of a log file you can expect to get from Kafka. All in json.
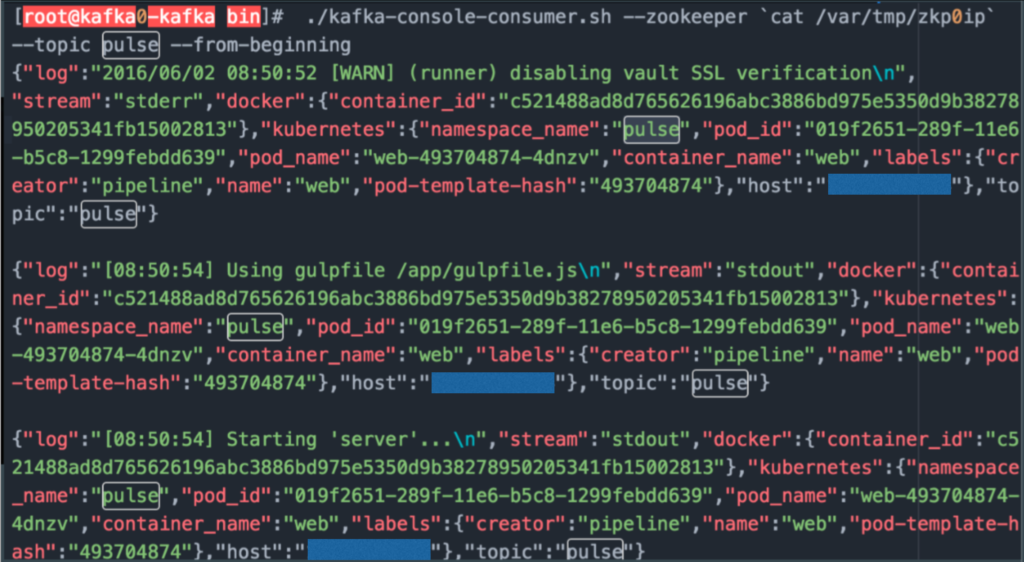
Alright so now that we have data being pushed to Kafka topic by namespace what can we do with it?
Next we’ll work on getting data out of Kafka.
Securing the Kafka endpoint so it can be consumed from anywhere.
And generally rounding out the implementation.
Eventually we hope Kafka will become an endpoint by which logs from across the organization can be consume. But naturally, we are starting bitesized.
Please follow me and retweet if you like what you see. Much appreciated.
@devoperandi