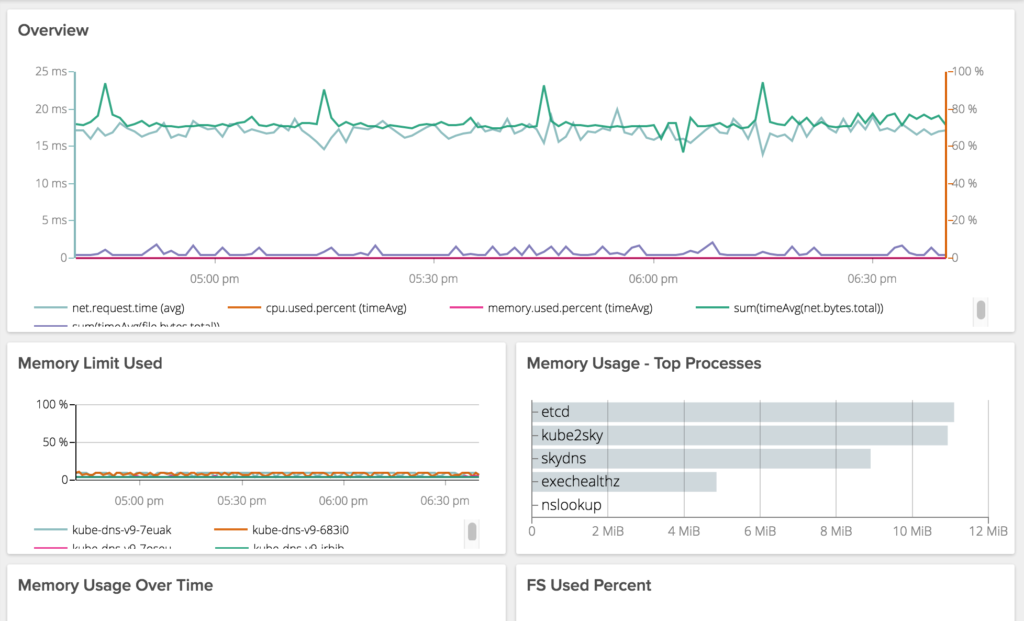
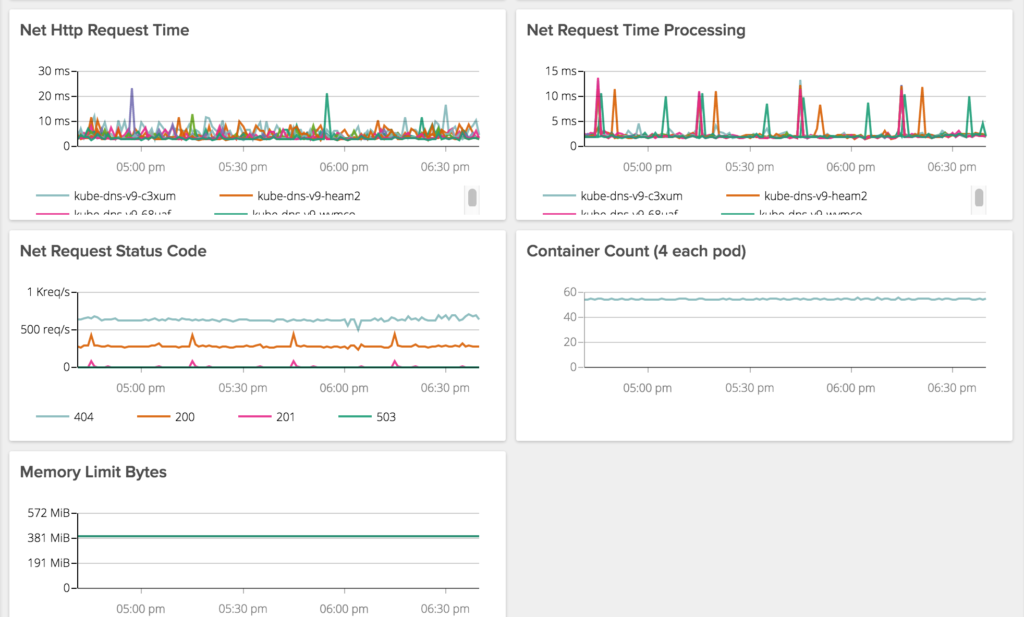
Ok so this is going to be a tough one to write but I’m going to do it anyway. This is a story of data overload, a shit ton of rabbit holes, some kick ass engineers and a few hours of my life I hope not to repeat. I never cease being amazed by how one thing can cause so much trouble.
Requirements:
- Using Kube-DNS for internal DNS resolution. I assume this to be most of my audience.
- Running Nginx Ingress Controllers for Reverse Proxy
If your environment doesn’t fit the bill on either of the above, you can probably ignore this terribly written yet informative post.
Our team recently took what I would call a partial outage as a result of this problem. I can’t, nor would I want, to go into the details around how long. 🙂 But needless to say we went through a lot of troubleshooting and I can only hope this will help someone else.
It all started out on a beautiful sunny Colorado day………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………… Nevermind. You probably don’t want to hear the ramblings of a terrible doesn’t-wanna-be-a-writer who can’t write.
So lets get to the symptoms.
Symptoms included:
Higher than normal Network Response Times for applications.
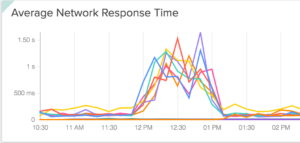
Some domains worked and some don’t.
In the course of this troubleshooting we noticed that some domains worked and some didn’t. I mean like 100% of the time they worked. No errors. No problems. Take for example all our CI/CD applications and our documentation site. They all worked without fail. All these things are on the same platform. The only difference is their endpoint urls.
….or so it seemed.
To make matters worse, we had my-app-blue.prsn.io, my-app-green.prsn.io (blue/green deploys) AND my-app.prsn.io.
We could hit the blue and green endpoints just fine but my-app.prsn.io would err a portion of the time.
Here is the kicker, my-app-blue.prsn.io and my-app.prsn.io literally route to the same exact set of pods. Only difference is the endpoint url.
Tons of NXDOMAIN requests (more than normal):
What is an NXDOMAIN?
The NXDOMAIN is a DNS message type received by the DNS resolver (i.e. client) when a request to resolve a domain is sent to the DNS and cannot be resolved to an IP address. An NXDOMAIN error message means that the domain does not exist.
1. dnsmasq[1]:179843192.168.154.103/52278 reply my-app.my-base-domain.com.some-namespace.svc.cluster.local is NXDOMAIN
Now notice the event above shows
my-app.my-base-domain.com.some-domain.svc.cluster.local
This is because the resolver could not find
my-app.my-base-domain.com
so it attempted to add its default domain of “name-space.svc.cluster.local”
resulting in a string of NXDOMAINs like so:
dnsmasq[1]: 179861 192.168.125.227/43154 reply my-app.some-external-endpoint.com.svc.cluster.local is NXDOMAIN dnsmasq[1]: 179863 192.168.125.227/43154 reply my-app.some-external-endpoint.com.svc.cluster.local is NXDOMAIN dnsmasq[1]: 179866 192.168.71.97/55495 cached my-app.some-external-endpoint.com.cluster.kube is NXDOMAIN dnsmasq[1]: 179867 192.168.120.91/35011 reply my-app.some-external-endpoint.com.cluster.local is NXDOMAIN dnsmasq[1]: 179869 192.168.104.71/40891 reply my-app.some-external-endpoint.com.cluster.local is NXDOMAIN dnsmasq[1]: 179870 192.168.104.71/57224 reply my-app.some-external-endpoint.com.cluster.local is NXDOMAIN
This is because Kubernetes ndots:5 by default. More on that here.
Next we found Domain Resolution Errors
A comment from a teammate:
I suspect it's DNS. Possibly ours, but I can't be sure where or how. Things are resolving fine internally presently and even externally... But ingresses clearly log that they can't resolve certain things.

Now this we could gather this from the increase in NXDOMAIN events but this provided a more clarity as to what we were looking at.
Another teammate:
we know that kubedns pods resolve *external* dns entries fine
you can make sure of that running
nslookup www.whatevs 127.0.0.1
on kube-dns pods
SO how in the hell do we have Nginx-controller throwing domain resolution errors but we can resolve anything we like just fine from the fucking DNS server itself?
In the mean time we got some more data.
We also saw Throttling at the API Server:
Throttling request took 247.960344ms, request: GET:http://127.0.0.1:8080/api/v1/namespaces/app-stg/pods Throttling request took 242.299039ms, request: GET:http://127.0.0.1:8080/api/v1/namespaces/docs-prd/pods?labelSelector=pod-template-hash%3D2440138838%2Cservice%3Dkong-dashboard Throttling request took 247.059299ms, request: GET:http://127.0.0.1:8080/api/v1/namespaces/otherapp-dev/configmaps
which caused us to have a look at ETCD.
ETCD likely Overloaded:
W | etcdserver: server is likely overloaded W | etcdserver: failed to send out heartbeat on time (deadline exceeded for 129.262195ms) W | etcdserver: server is likely overloaded W | etcdserver: failed to send out heartbeat on time (deadline exceeded for 129.299835ms)
At this point here is what we’ve got:
- Network response times have increased
- Some domains are working just fine but others aren’t
- NXDOMAIN requests have increased
- Domain resolution errors from Nginx
- DNS resolution from ALL Kube-DNS pods work just fine
- API Server is throttling requests to save ETCD
Data points we missed:
- Domain endpoints that were under load failed more often
So what was the problem?
Next stop, Nginx.
Here is what bit us. For each backend in Nginx, a socket will be opened to resolve DNS. Identified by the line with “resolver” in it like below. This socket has a TTL of 30 seconds by default. Meaning if the something happens to the DNS resolver (kube-dns pod), Nginx will fail away from it in 30 seconds UNLESS retries are configured. IF retries are configured, the 30 second TTL will be reset every time a retry takes place. As you can imagine, Nginx ends up keeping the socket open almost indefinitely under high load and thus never creates a new socket to a kube-dns pod that is up and available.
Ours was set to:
resolver kube-dns.kube-system.svc.cluster.local;
Big mistake.
You see, resolving the resolver is well, bad form. Not to mention likely to cause a shit ton of head aches. It did for us.
What about adding
valid=10sat the end of the resolver line sense we are setting a domain variable? Only works for proxy_pass. Not for the resolver itself.
Ok fine, what options do we have? We thought of three.
- Add Kube-DNS/dnsmasq pod as a daemonset and have it added to every server. Not a bad idea over all. The IP could be setup to listen over the Docker socket and thus be static across all hosts. But this does present challenges. For example, we’ll still end up in a Chicken and Egg scenario especially if using things like a Private Docker Registry as a Kubernetes Pod in our cluster as we do.
- Running dnsmasq on every server with systemd and still have it available over the docker socket. Thus allowing for a statically assigned IP that can be set in Nginx. This also has the advantage of significantly reducing the number of DNS requests that make it to kube-dns, distributes the load and almost makes DNS significantly less hassle. It however does mean we wouldn’t be running it as a container. This also has the added benefit of being able to place dnsmasq on any server outside the Kubernetes world, thus allowing for a little bit more consistency across the platform.
- Run dnsmasq as a sidecar to all Nginx pods could be a valuable option as well. It lacks the availability of option #2 but it means Nginx could simply look at local loopback address for resolving DNS. It also has the added benefit of having Kubernetes automatically reschedule the container should it fail.
Alright, what did we pick?
**NOTE** we have changed and moved to running dnsmasq as a sidecar along side the Nginx container.
At this time we are using Option #2. Easy to setup, provides continuity across our platform, reduces network traffic due to caching of DNS requests and did I mention it was easy to setup?
Note: There is work in progress by the Kubernetes folks around this. Although I’m not sure there has been a definitive solution just yet.
Hope this helps you and yours from hitting the same pitfall we did. GL
@devoperandi